AIモデル自動推論実行システムの構築方法について② SageMaker AIを使ったAIモデル作成

こんにちは。第三システム開発部新入社員の菊池です。
今回はAWSのサービス「SageMaker AI」を使ってAIモデルを構築する方法についてご紹介します。SageMaker AIとは、機械学習モデルの構築、トレーニング、運用を効率的に行うことができるサービスです。S3やLambdaなど、AWSの他のサービスと連携することで、複雑なアーキテクチャを構成することが可能です。
本記事は「AIモデル自動推論実行システムの構築方法について①」の続編です。前回の記事をまだお読みでない方は、ぜひそちらをご確認ください。
AIモデル自動推論実行システムの構築方法① | DX支援・IT推進・AWS共同開発 株式会社トラスト
目次
1.Tensorflowとは?
2.ノートブックインスタンスの作成
3.AIモデルの構築
4.AIモデルのテスト
5.ノートブックインスタンスの停止
1.Tensorflowとは?
トラストで活用しているAIモデルは、PythonとそのライブラリであるTensorFlowを使用して開発されています。
TensorFlow(テンソルフロー)とは、機械学習モデルの構築、学習、推論を可能にするPythonライブラリです。大規模なデータセットを効率的に扱えることが可能で、画像認識や自然言語処理、時系列データ解析など幅広い分野で活用されています。
今回は、MNISTデータセットを用いて画像分類モデルを構築します。MNISTはTensorFlowが提供する手書き数字の画像データセットで、各画像にはモノクロの0~9の数字が描かれています。このデータセットを活用し、画像内の数字が0~9のどれに該当するかを判定するAIモデルを作成します。
AIモデルの作成は、TensorFlowの公式チュートリアルを参考に進めます。ライブラリの機能やAIモデルの具体的な構築手順については、こちらをご確認ください。
https://www.tensorflow.org/tutorials/quickstart/beginner?hl=ja
2.ノートブックインスタンスの作成
こちらはSageMaker AIのコンソール画面です。
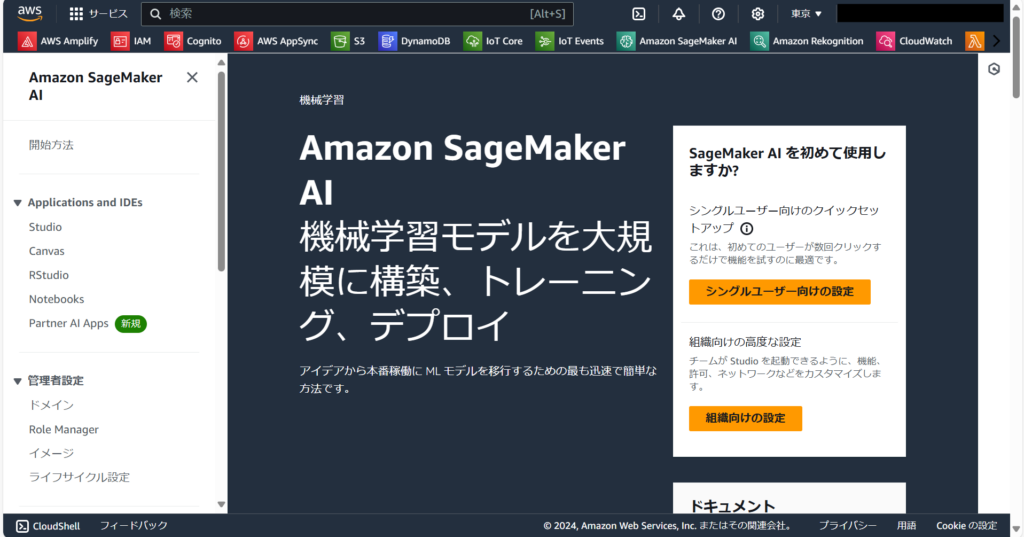
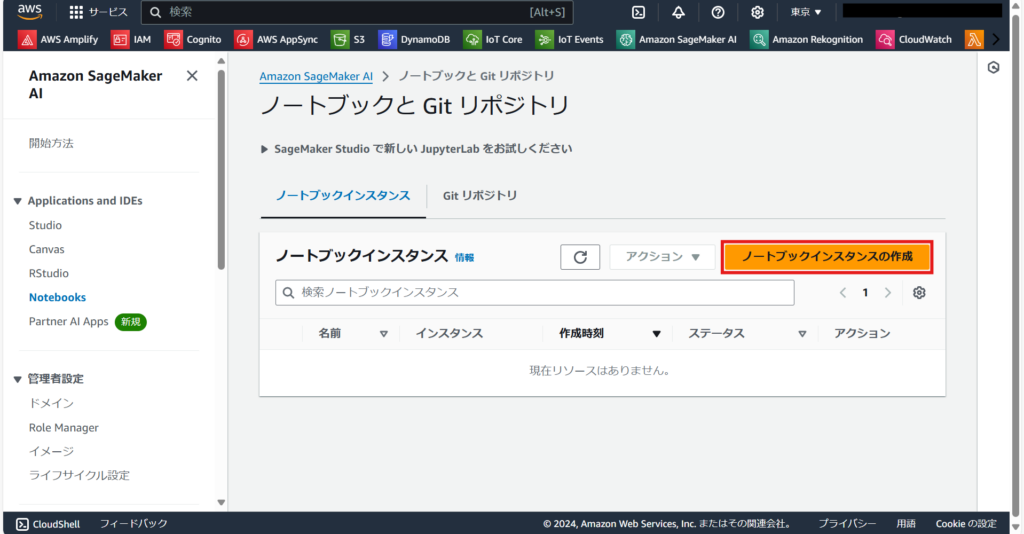
「Applications and IDEs → Notebooks」に移動し「ノートブックインスタンスの作成」からインスタンスを作成します。
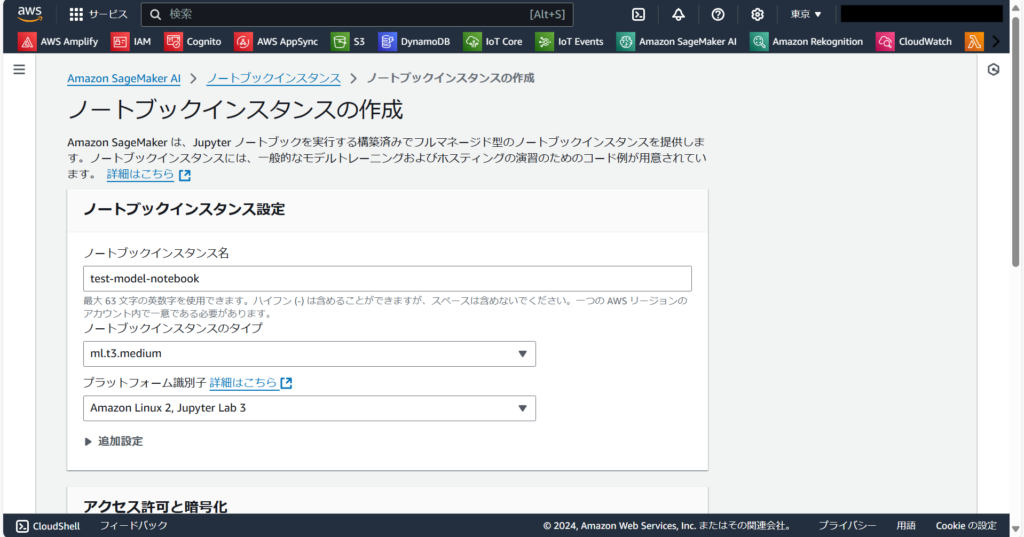
次に「ノートブックインスタンス名」「ノートブックインスタンスのタイプ」「ボリュームサイズ」を入力します。
ノートブックインスタンスのタイプは、必要な計算量に応じて選択します。前回の記事で紹介した異音検知モデルでは「ml.m5d.2xlarge」を使用しています。ボリュームサイズは「追加設定」から設定できます。使用するデータセットのサイズに応じて選択します。使用するインスタンスタイプの性能やボリュームサイズに応じて料金が発生する点にご注意ください。
今回作成するMNISTモデルは、計算量やデータセットのサイズは小さいため、ノートブックインスタンスのタイプとボリュームサイズはデフォルトのままで問題ありません。
インスタンスで使用するIAMロールを選択、または新しく作成します。
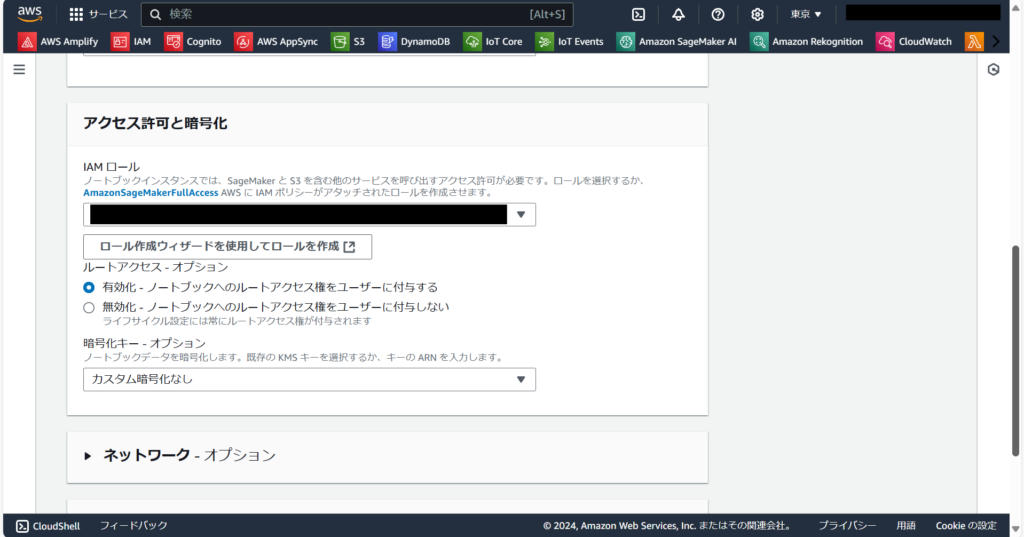
他にも設定可能な項目はありますが、今回はデフォルト設定で問題ありません。必要に応じて適宜設定してください。
設定が完了したら、ノートブックインスタンスを作成します。
ノートブックインスタンスを作成すると一覧に表示されます。モデルの作成状況はステータス欄から確認できます。ノートブックインスタンスの起動中は「Pending」、起動が完了すると緑色の文字で「InService」と表示されます。
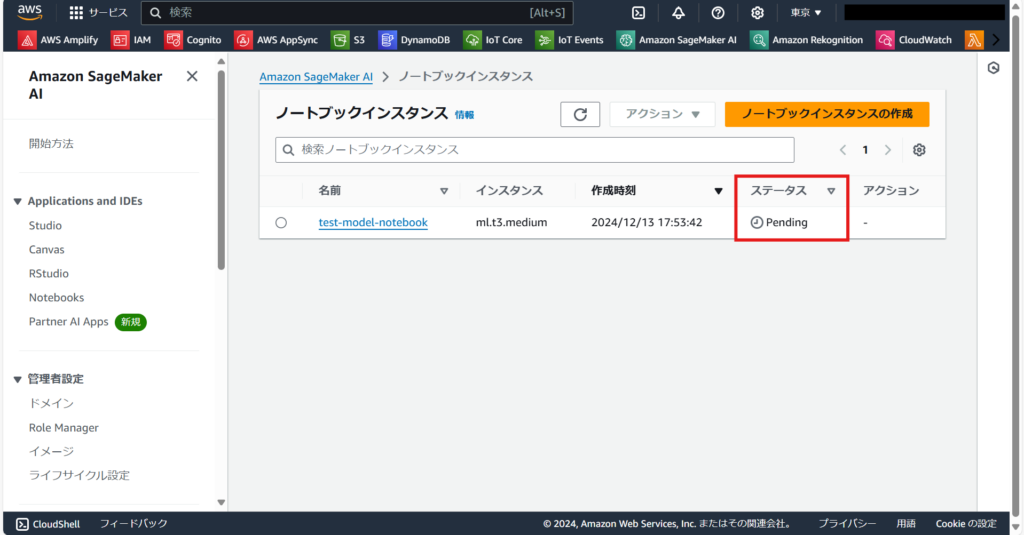
インスタンスが起動したらノートブックインスタンスを選択し、「JupyterLabを開く」を押します。
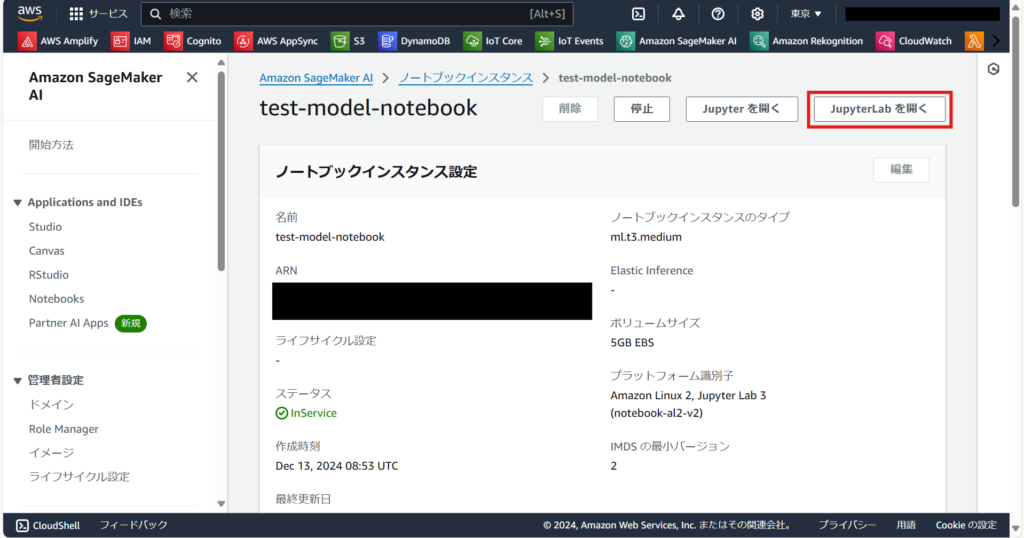
こちらはJupyterLabの画面です。Notebookで使用するカーネルを選択します。カーネルとは、Notebookのバックエンドで動作する環境の一種です。今回はtensorflowの環境が予め構築されている「conda_tensorflow2_p310」を選択します。tensorflow2とp310は、それぞれTensorflowとPythonのバージョンを表しています。

3.AIモデルの構築
作成したNotebook上でAIモデルを構築します。
使用するライブラリをインポートします。
import tensorflow as tfMNISTデータセットを読み込み、教師データとテストデータに分類します。xは画像データ、yは0~9のラベルデータで構成されています。
mnist = tf.keras.datasets.mnist
(x_train, y_train), (x_test, y_test) = mnist.load_data()画像データのピクセル値を0~1の範囲に変更します。変更することで、AIモデルの学習効率や計算の安定感が向上します。
x_train, x_test = x_train / 255.0, x_test / 255.0AIモデルを構築します。
model = tf.keras.models.Sequential([
tf.keras.layers.Flatten(input_shape=(28, 28)), # 入力データを1次元の配列に変換
tf.keras.layers.Dense(128, activation='relu'), # 活性化関数relu
tf.keras.layers.Dropout(0.2), # 20%をドロップアウト
tf.keras.layers.Dense(10, activation='softmax') # 活性化関数softmax。出力層のユニット数を、分類するグループ(0~9)の数に合わせる
])- Sequential:tensorflowで提供されるモデル構築用クラスの一種。入力層から出力層まで順次処理を行うモデルを構築する。
- Flatten:入力データを1次元の配列に変換する。AIモデルは1次元データを扱うため、2次元以上のデータを1次元に直す処理が必要。
- Dropout:ユニットの値をランダムで無効化し、過学習を防止する。
Softmax関数は、分類問題の出力層で使用される活性化関数で、出力された値が確率として表現されます。最も高い確率を持つ値が、最終的な分類結果となります。例えば、出力された配列の中で最大値のインデックスが3であれば、AIモデルは画像に描かれた数字を「3」と判断したことになります。
AIモデルをコンパイルします。
loss_fn = tf.keras.losses.SparseCategoricalCrossentropy(from_logits=True) # 損失関数を定義
model.compile(optimizer='adam', # 最適化関数Adam
loss=loss_fn, # 損失関数
metrics=['accuracy']) # 評価指標- SparseCategoricalCrossentropy:多クラス分類で使用される損失関数のひとつ。クラスラベルが整数(今回は0~9)で与えられている場合に使用される。
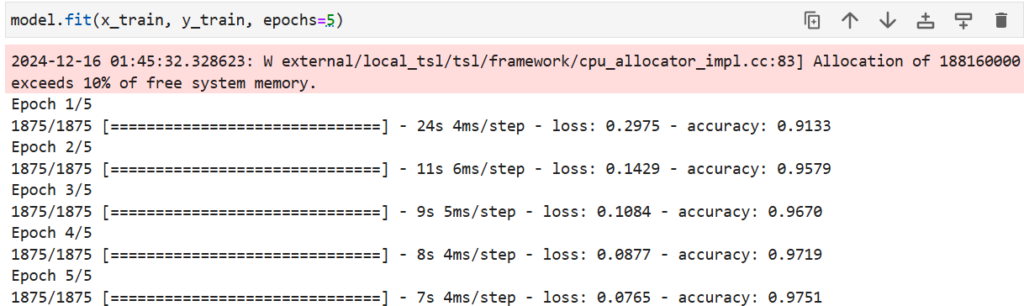
AIモデルを学習させます。
model.fit(x_train, y_train, epochs=5)以下のように学習過程が表示されます。
学習させたモデルを保存します
model.save("./test-model.keras")実行すると、Notebookのディレクトリにモデルが保存されます。
4.AIモデルのテスト
保存したモデルを読み込みます
loaded_model = tf.keras.models.load_model("./test-model.keras") # モデル読み込み
loaded_model.summary() # モデルの詳細を表示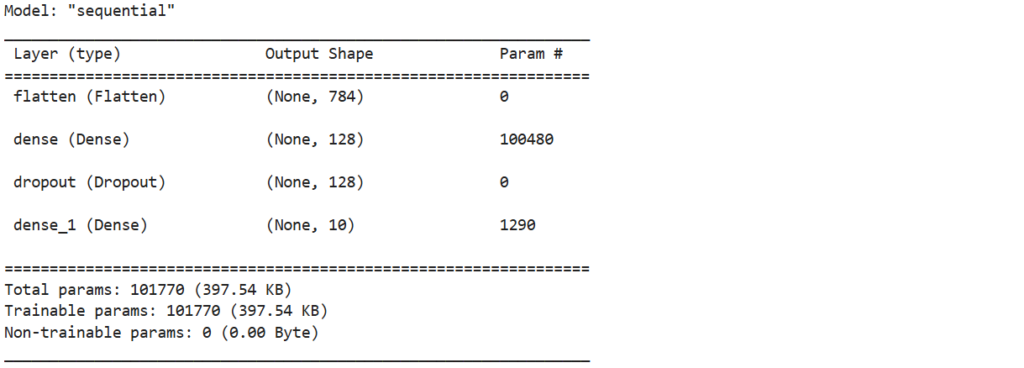
テスト用データを使って、AIモデルの予測を実行します。
def prediction_number(start, end):
prediction_class = [] # 予測結果用
label = [] # 正解ラベル
predictions = loaded_model(x_test[start:end]) # 予測を実行
for prediction in predictions:
predicted_class = np.argmax(prediction) # 最も確率が高いクラスを取得
prediction_class.append(predicted_class)
# 正解ラベルを取得
for true_label in y_test[start:end]:
label.append(true_label)
print("予測結果:", prediction_class)
print("正解ラベル:", label)
prediction_number(0,5)出力結果は以下のようになります
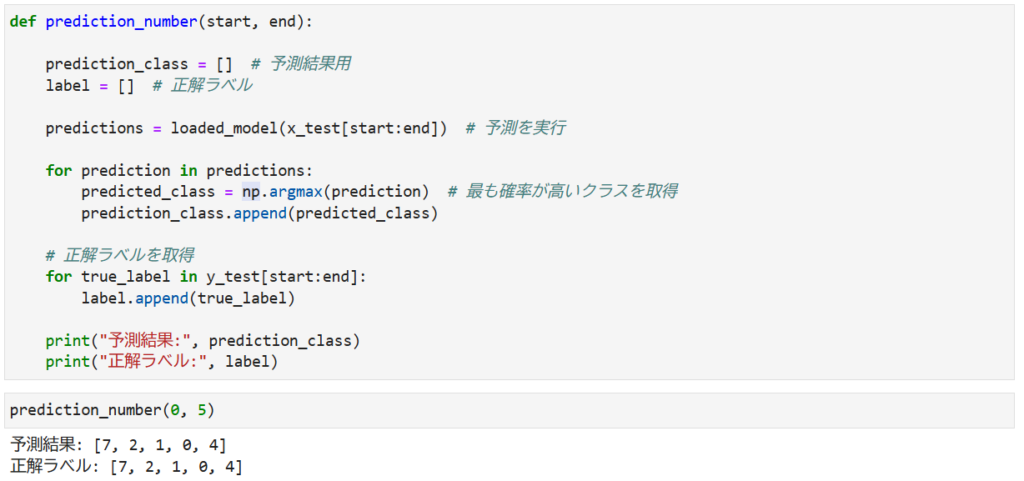
AIモデルの予測結果と正解ラベルが一致していることが確認できました
5.ノートブックインスタンスの停止
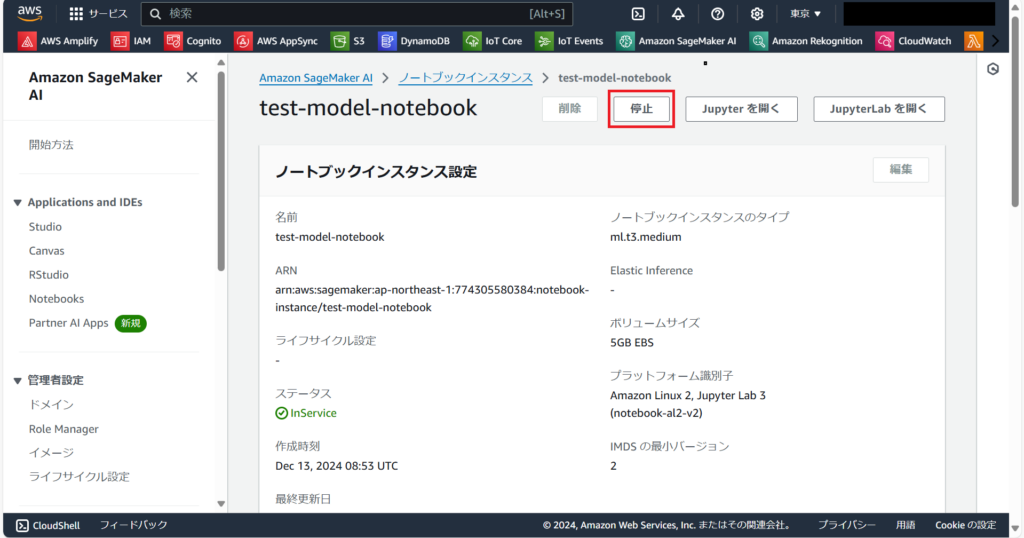
ノートブックインスタンスを使用し終えたら、必ず停止しましょう。インスタンスが起動している間は料金が発生するため、利用しないときに停止することで、無駄なコストを抑えられます。
インスタンスを停止すると、そのステータスは「stopping」を経て「stopped」に変化します。
まとめ
今回は、SageMakerとPythonのライブラリTensorFlowを用いたAIモデルの作成方法についてご紹介しました。次回の記事では、今回作成したモデルを活用し、AIによる推論を自動実行するシステムの構築方法をお伝えします。
最後までお読みいただき、ありがとうございました。今後もAIに関する情報を発信してまいりますので、次回の記事もぜひご期待ください。


