Amazon Bedrockのナレッジベース(ベクトルデータベース)を無料利用枠内で簡単に構築する方法

はじめに
株式会社トラスト、AWSソリューションアーキテクト兼AI・MLエンジニアの高宮です。
今回は、「AWSの生成AIアプリ作成ツールであるAmazon Bedrockを使って簡単にRAGシステムを構築する方法」でご紹介した内容を完全サーバレスで実現する方法をご紹介します。
この記事で扱う内容は以下の通りです。
目次
1.ベクトルデータベース is 何?
2.RAGにおけるベクトルデータベースの役割
3.一般的なベクトルデータベース構築の流れ
4.Pineconeとは?
5.Pineconeでユーザー登録する
6.AWS MarketplaceでPineconeのサブスクライブ
7.ベクトルデータベースを構築
8.Bedrockのナレッジベースと連携する
9.最後に
10. 参考文献
1.ベクトルデータベース is 何?
そもそもベクトルデータベースとは何でしょうか?
claude3.5 sonnetに聞いてみました。
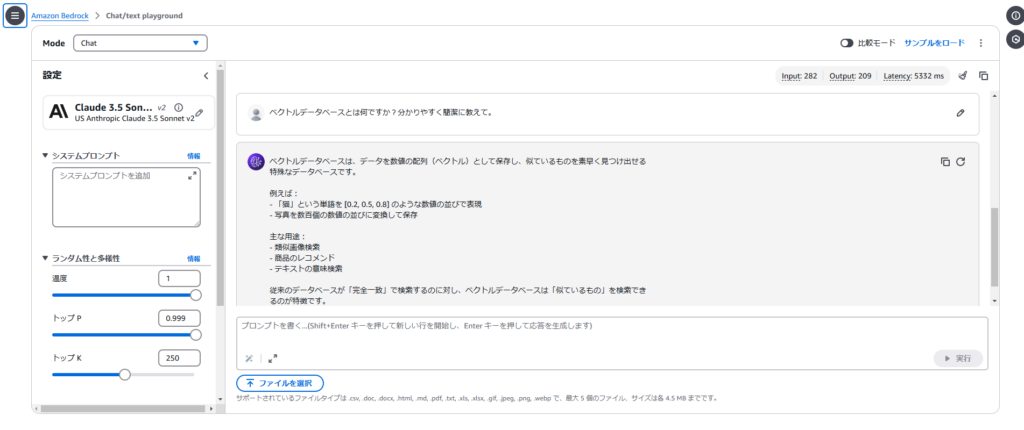
以下回答
ベクトルデータベースは、データを数値の配列(ベクトル)として保存し、似ているものを素早く見つけ出せる特殊なデータベースです。
例えば:
-「猫」という単語を [0.2, 0.5, 0.8] のような数値の並びで表現
-写真を数百個の数値の並びに変換して保存
主な用途:
-類似画像検索
-商品のレコメンド
-テキストの意味検索
従来のデータベースが「完全一致」で検索するのに対し、ベクトルデータベースは「似ているもの」を検索できるのが特徴です。AWS公式がこちらの記事 https://aws.amazon.com/jp/what-is/vector-databases/ を出しているので、興味がある方はご覧ください。
2.RAGにおけるベクトルデータベースの役割
RAGベクトルデータベースの担当範囲は以下の赤枠になります。
質問に対する回答のほとんどを担当していることが分かりますね。
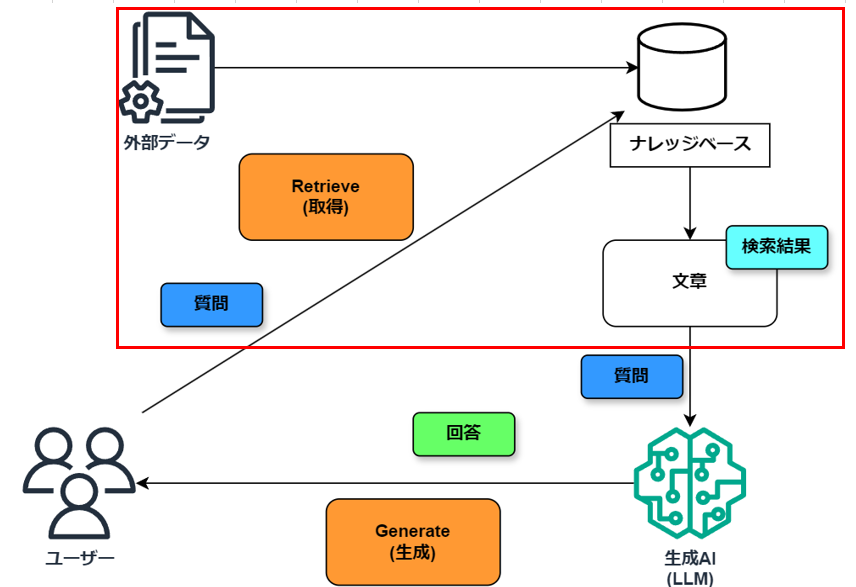
3.一般的なベクトルデータベース構築の流れ
1.元のデータを検索に適した小さなセグメントに分割します。
このセグメントはチャンクと呼ばれ、このステップはチャンキングと呼ばれます。
2.チャンクをセマンティックサーチが可能なベクトルデータへ変換します。この変換は埋め込み (embedding) モデルを使って行われます。
埋め込みモデルは、単語や文章などのテキストデータを、高次元のベクトル空間内の点として表現します。
3.この空間内では、意味的に類似したテキストデータは近くに位置するように学習されます。
つまり、似た意味を持つ文章は、ベクトル空間内で近くに位置することになります。
このようにして得られたベクトル表現を使うことで、2 つの文章の類似度を計算することができます。
4.次に、このベクトル表現をベクトルデータベースの索引 (index) に登録することでナレッジベースが構築されます。基本的にベクトルデータベースは上記流れで構築します。
前回の「AWSの生成AIアプリ作成ツールであるAmazon Bedrockを使って簡単にRAGシステムを構築する方法」では、このあたりをコンソールから実行しました。簡単に構築できるのはメリットですが、Open Search Serviceを使用するため使っていなくても課金されるデメリットがありました。そこで、今回はAWS Marketplace の Pineconeを使って無料利用枠内でナレッジベースを構築していきます。
4.Pineconeとは?
以下、AWS公式から引用。
Pinecone は、高次元のベクトルデータを扱うための、クラウドネイティブでスケーラブルなベクトルデータベースです。
ベクトルデータベースの索引の中のからクエリに最も近い文書を検索する際、総当たりのアルゴリズムを用いることもできますが、非常に多くのコンピューティング資源を消費してしまい、大規模なベクトルデータベースではスケーラビリティに問題があります。Pinecone の基本的なアプローチは、ANN (Approximate Nearest Neighbor; 近似最近傍) 検索に基づいており、大規模なデータセット内でより高速にマッチする文書を効率的に見つけ、ランク付けすることができます。料金体系は以下です。

今回は使った分だけ課金される「Serverless プラン」で構築していきます。実証実験レベルのドキュメント量であれば無料利用枠内でRAGが構築出来ます!
では実際に構築していきましょう。
5.Pineconeでユーザー登録をする
Get Startedからユーザー登録を進めます。
いくつか質問されるので、回答します。
ダッシュボードまで辿り着けばPineconeの登録は完了です。
6.AWS MarketplaceでPineconeのサブスクライブ
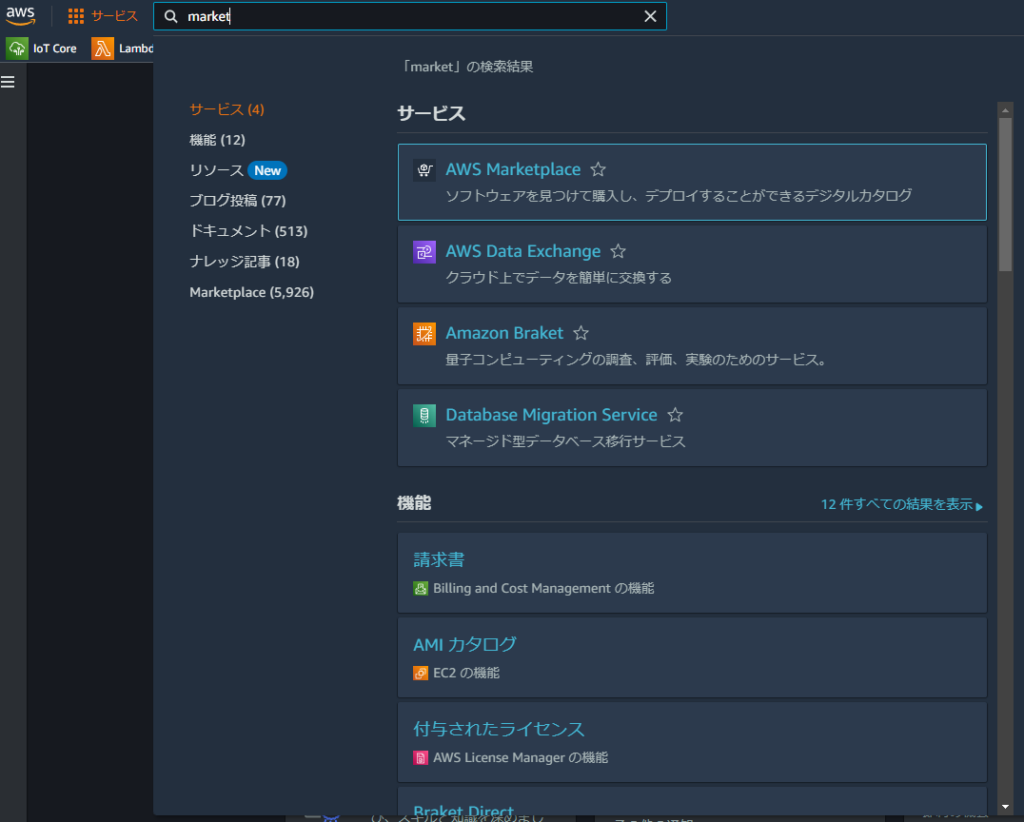
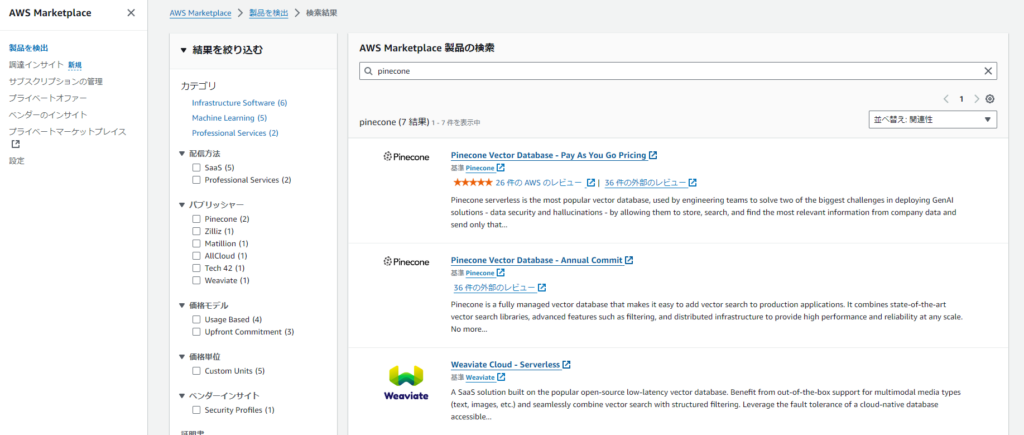
製品を検出からPineconeを検索します。
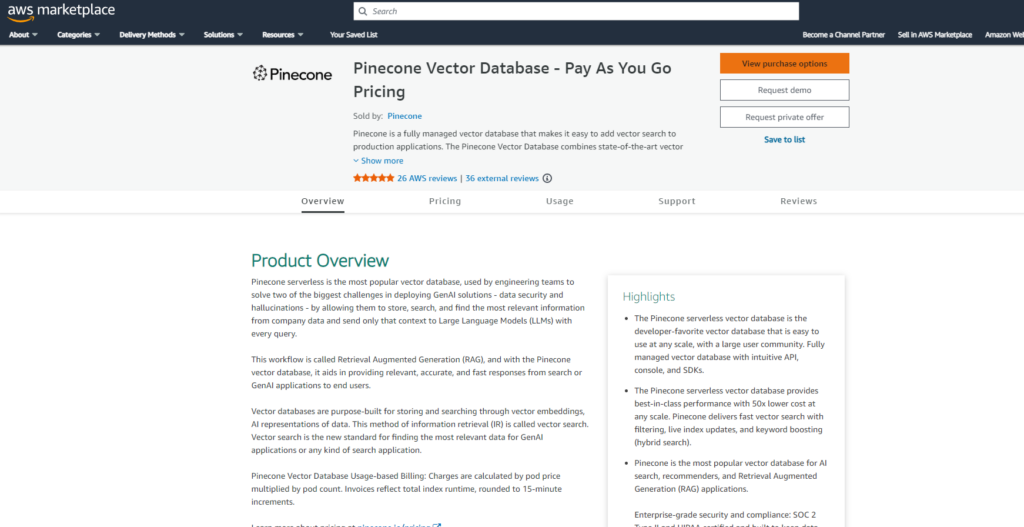
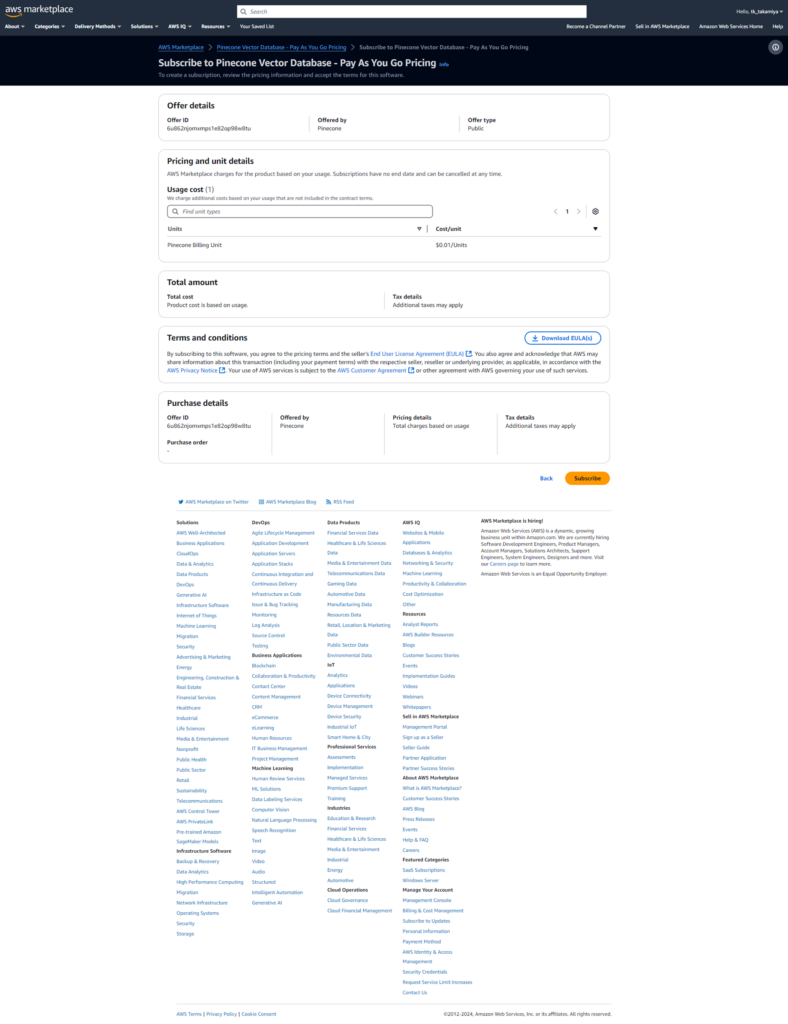
subscriveボタンを押下します。

上記のSet up your accountを押下します。
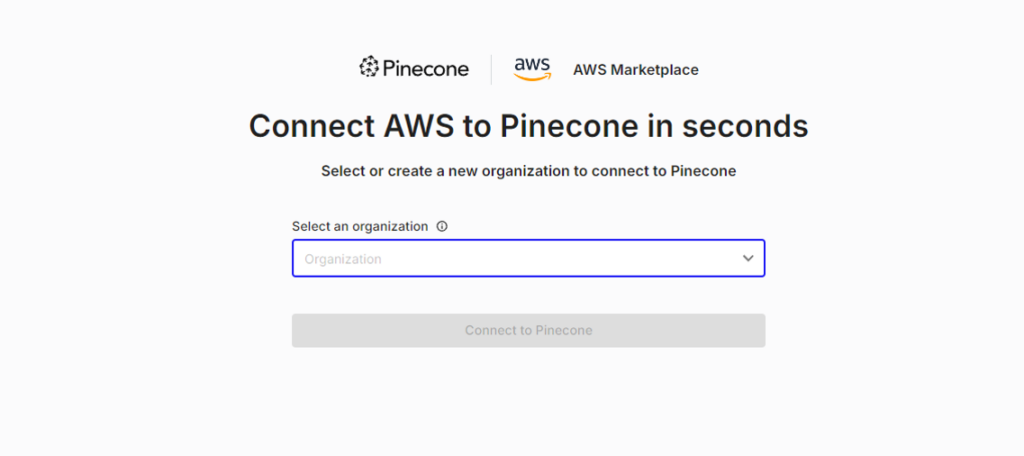
先ほど作成したアカウントと紐付けます。
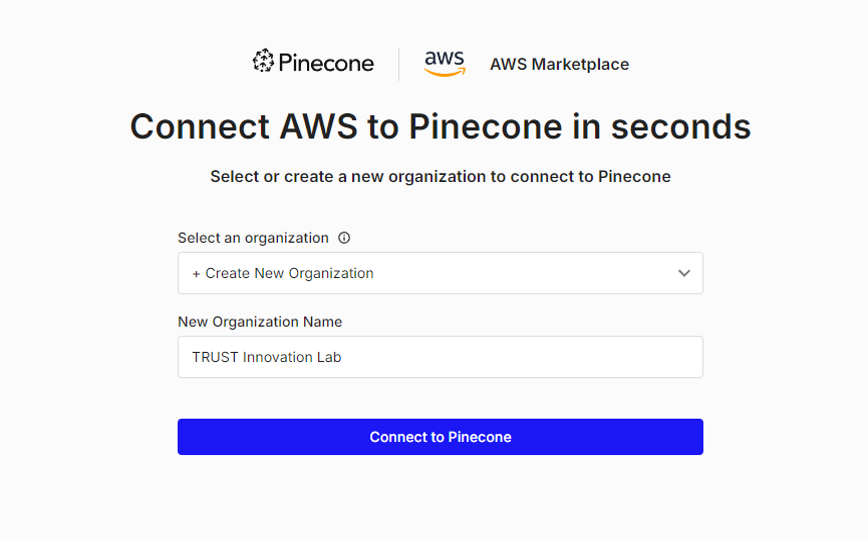
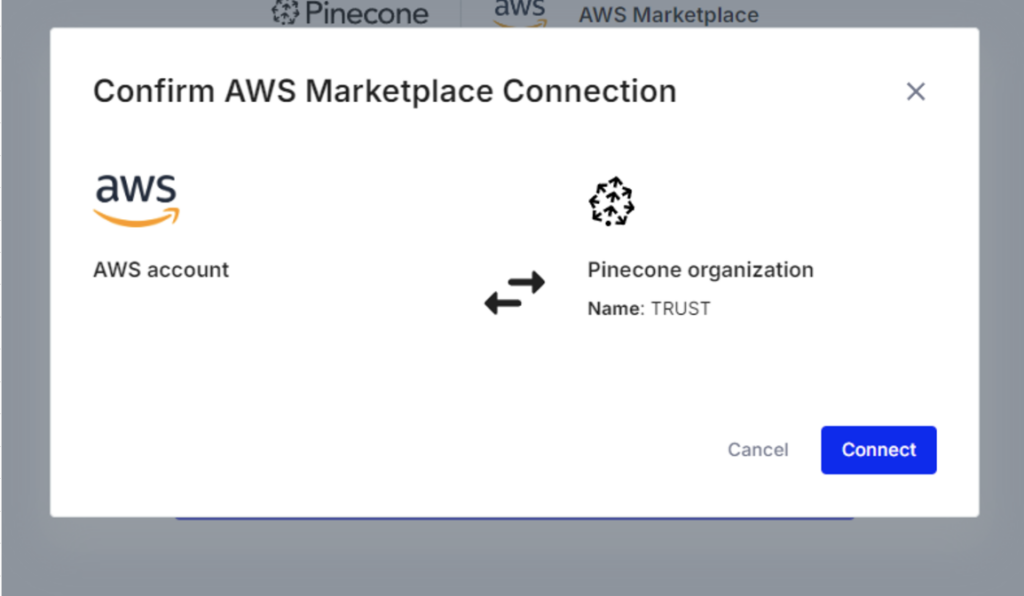
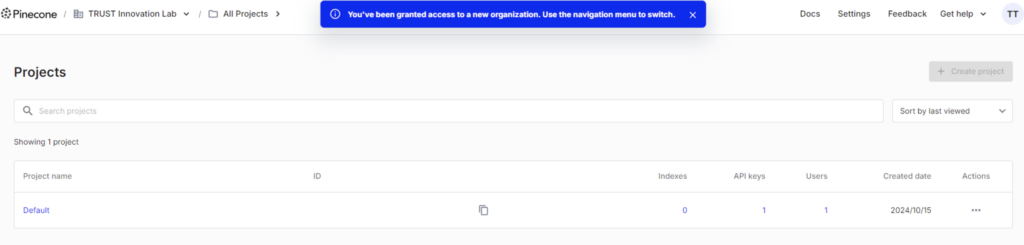
上記画面が表示されれば連携完了。
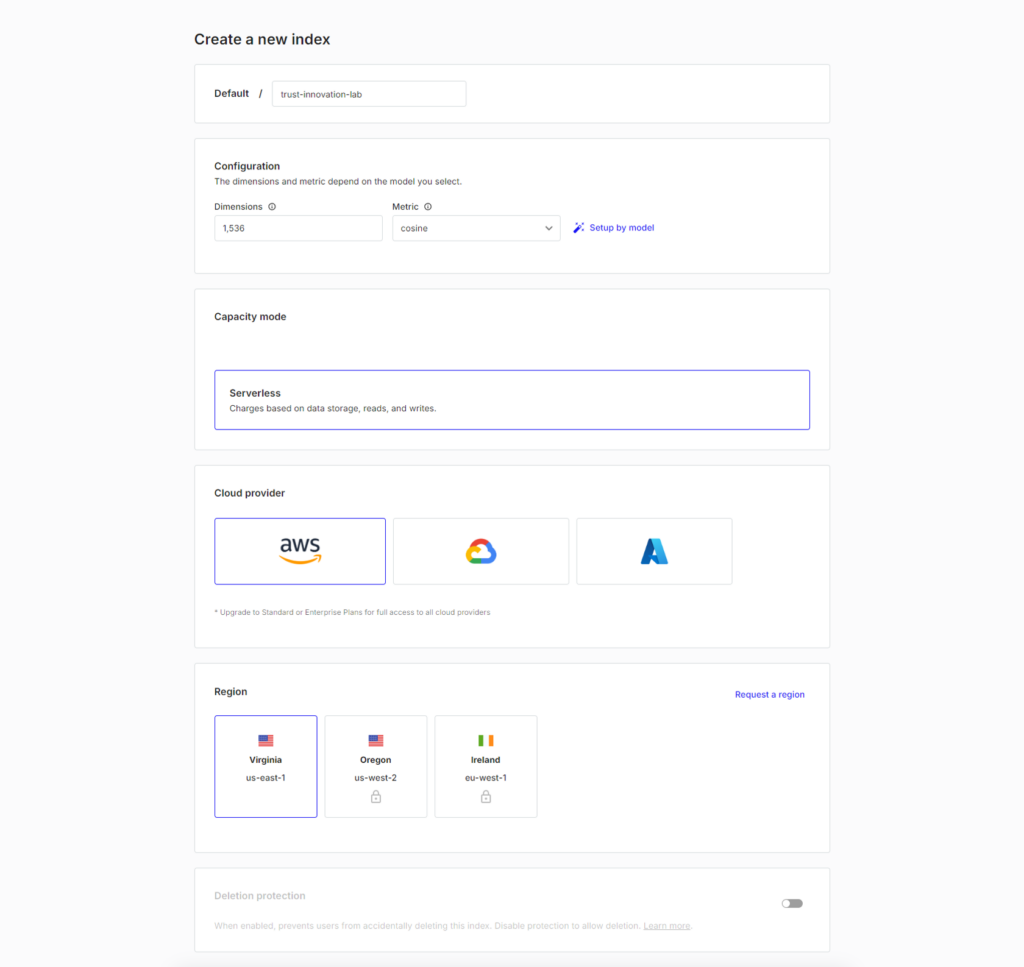
7.ベクトルデータベースを構築
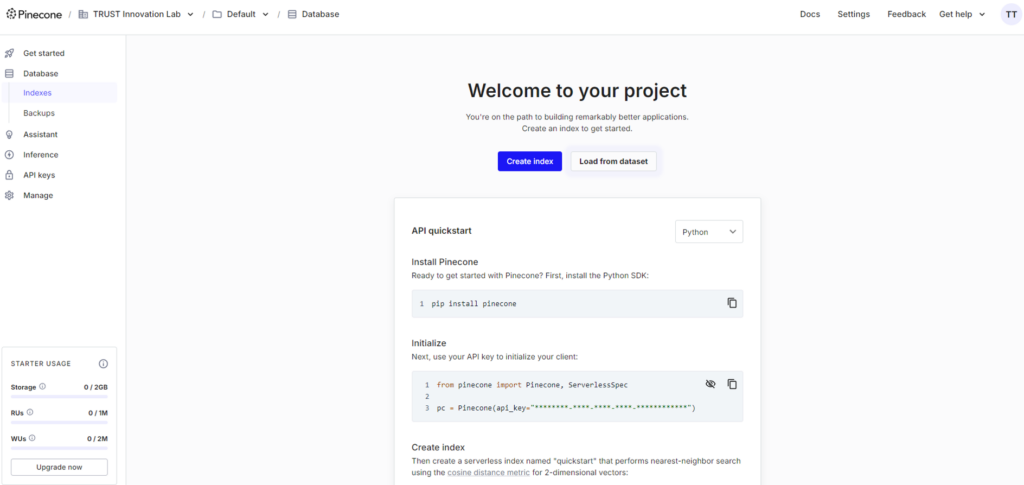
Create indexを押下する。
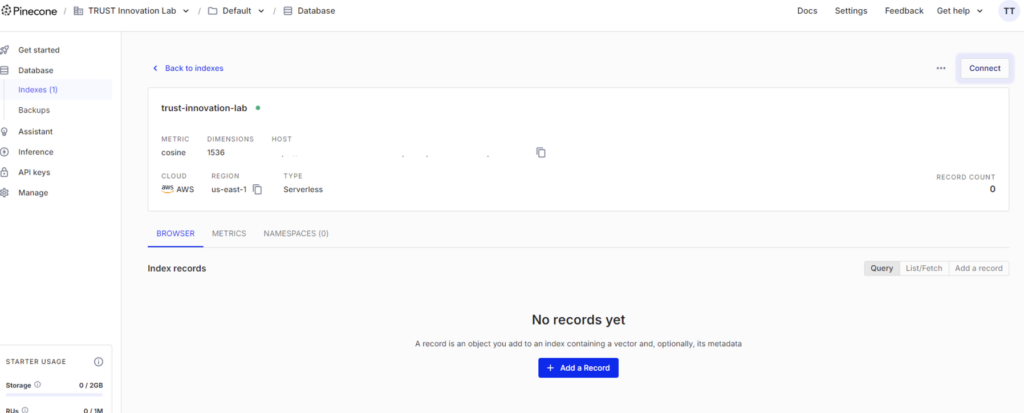
空のベクトルデータベースが完成しました。
8.Bedrockのナレッジベースと連携する
こちらは以前に記事同様、AWSのコンソール画面から進めます。
はじめの手順は以前の記事と同様なため、スクショのみ添付します。
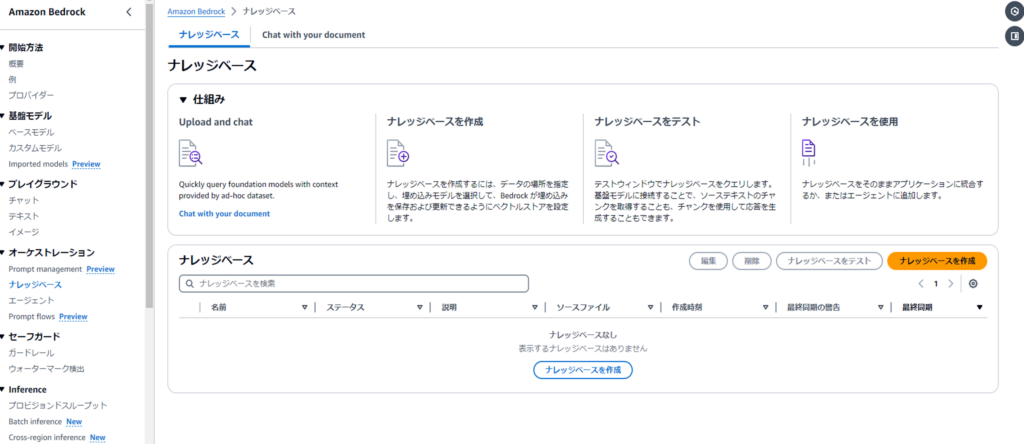
ナレッジベース作成を押下する。
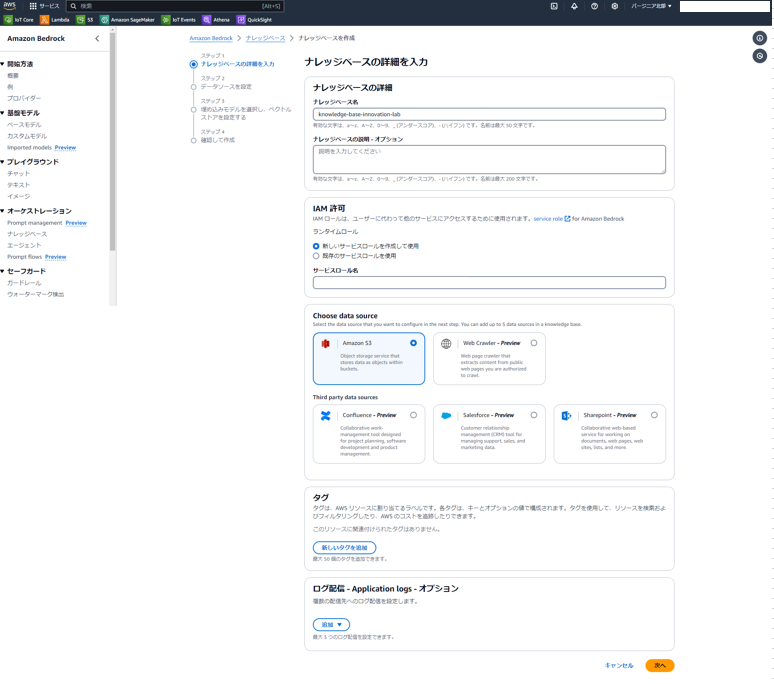
上記画面で次へを押下したあと、pineconeのコンソールに戻り、API Keyを取得します。

valueの部分をコピーボタンでコピーし、AWSコンソールに戻りAWS Secrets Managerを開きます。

先ほどコピーしたapikeyを添付します。
bedrockのナレッジベースで関連づけするため、分かりやすい名前で保存します。
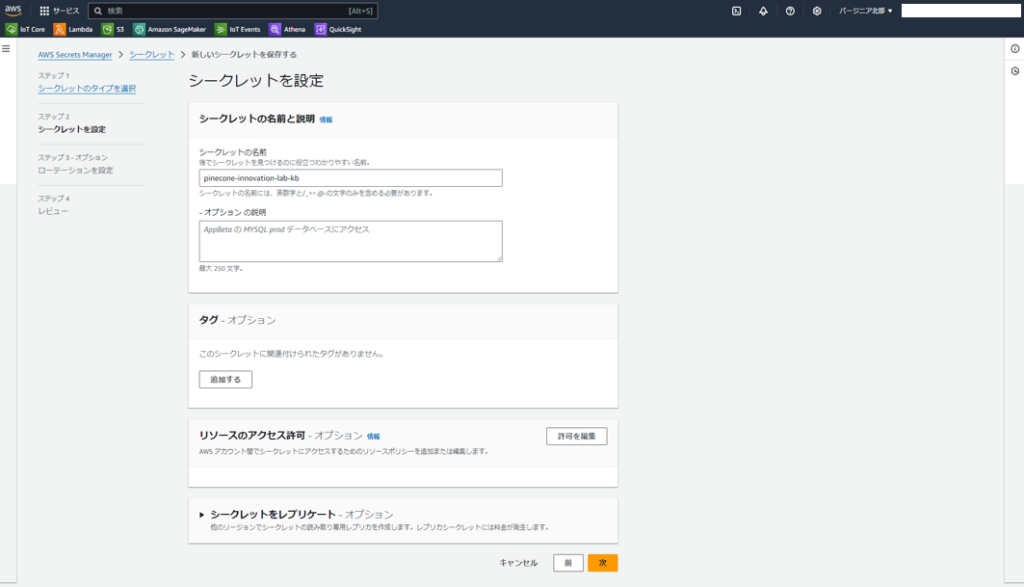

ローテーションの設定はデフォルトのままで次へ。
保存で完了。

ナレッジベースの連携画面に戻ります。
埋め込みモデルを選択し、
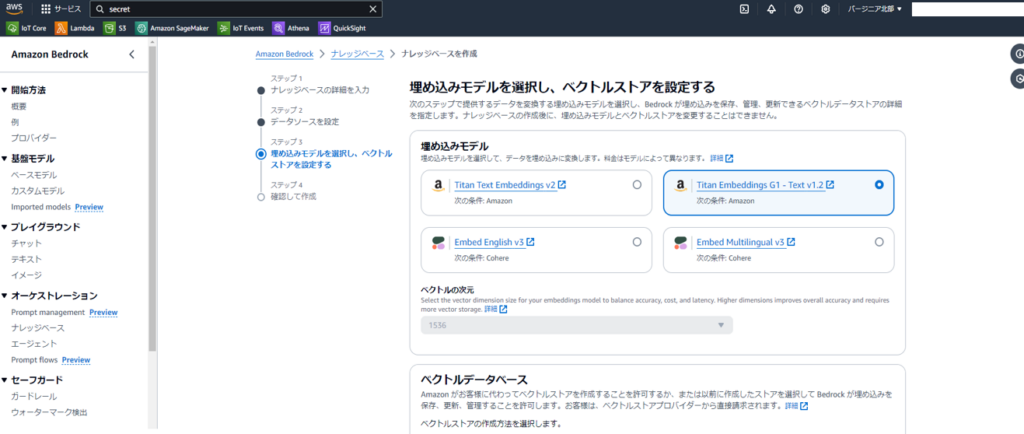
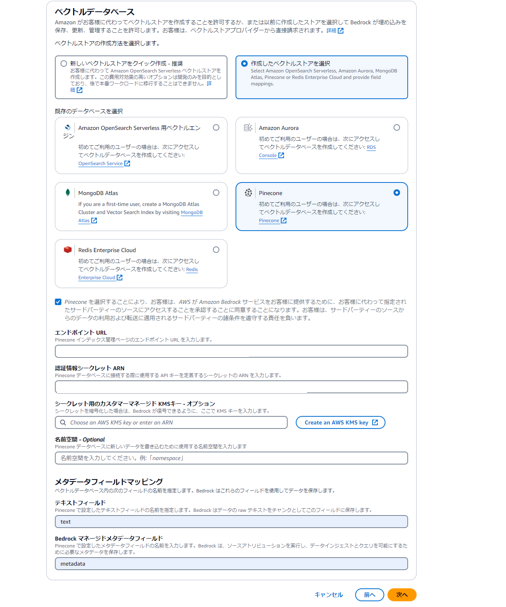
pineconeを選択、エンドポイントURLと認証情報シークレットARN(先ほど作成したもの)を入力し次へ。
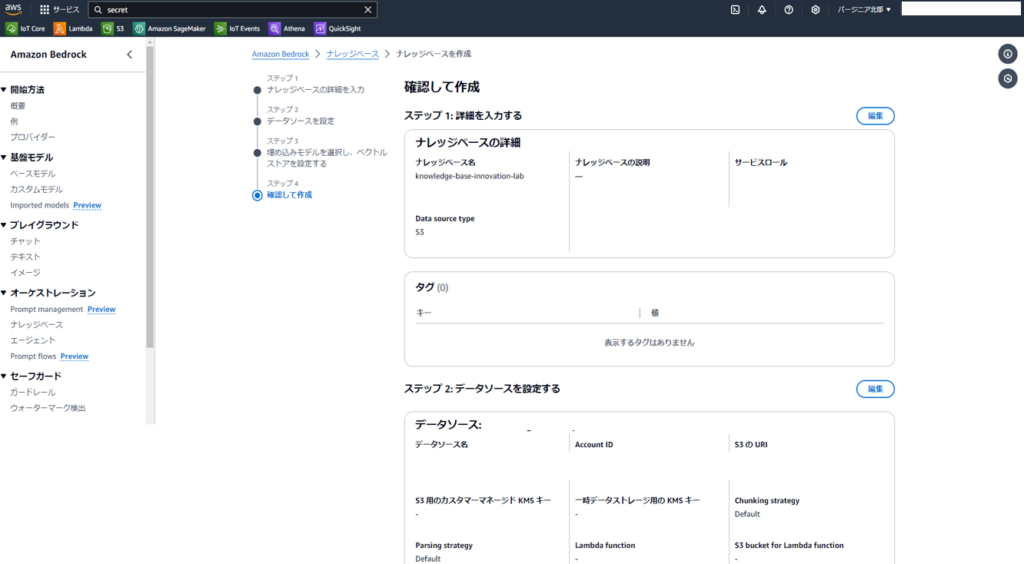
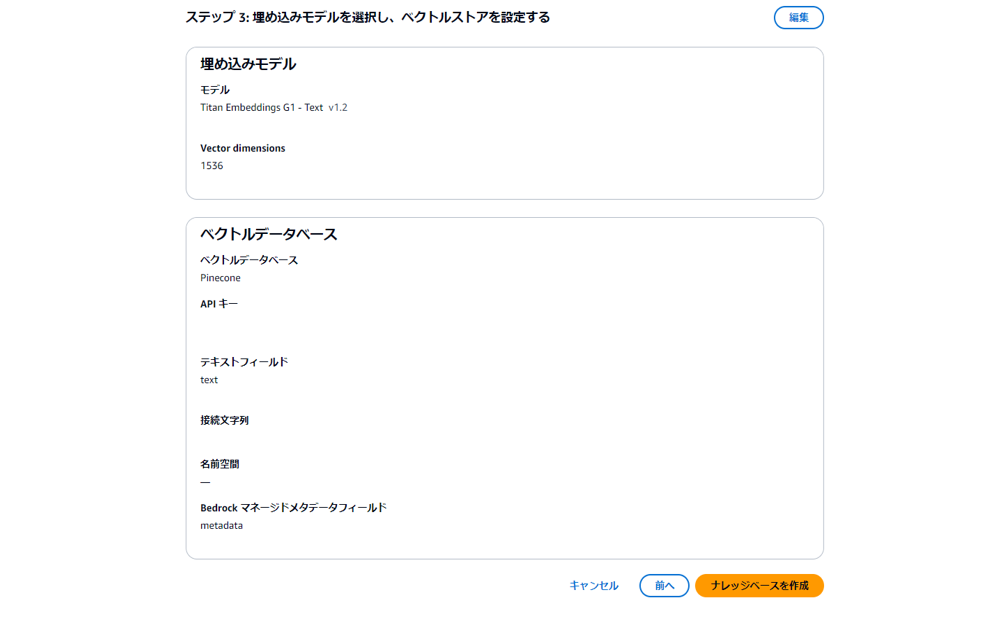
以下の確認画面が表示されるので、ナレッジベースを作成を押下すれば完成!
「ナレッジベースをテスト」から回答が生成されるようになります。
以上、Amazon Bedrockのナレッジベース(ベクトルデータベース)を無料利用枠内で簡単に構築する方法でした!
9.最後に
トラストではAI、IoTシステムのコンサル・開発を行っています。
社内文書検索を作成したい!RAGシステムを構築したい!などご要望がありましたら、お気軽にお問い合わせください。


