AWS SageMaker × AWS IoT Greengrassで実現するリアルタイム異音検知 〜Raspberry Pi 5でエッジ推論〜

こんにちは。ソリューションアーキテクトの髙宮です。
今回は弊社のソリューションの1つである異音検知システムについて、自動車のホーンを製造するお客様で採用した技術についてご紹介します。
プロジェクトの背景と目的
本プロジェクトでは、これまで人が行っていた自動車ホーンの音質検査を、エッジAIシステムによってリアルタイムに判定する仕組みを開発しました。
異音検知をクラウドではなくエッジ(端末側)で行う理由は、主に以下の通りです。
- リアルタイム処理が可能
クラウドへ音データを送信・応答を待つ時間が不要なため、検査結果を即座に判定できる。 - 通信コストの削減
大容量の音データを逐次クラウドへ送信する必要がなくなり、通信コストを抑えられる。 - ネットワーク障害の影響を受けにくい
工場や作業現場などでネットワーク環境が不安定な場合でも、エッジ側で安定して処理できる。 - プライバシー・セキュリティの強化
音データなどの機密情報をクラウドに送信せず、端末内で処理するため、情報漏洩リスクを低減できる。 - スケーラビリティと柔軟性
各端末にAIモデルを配布・更新できるため、設備の増設やモデル改善に柔軟に対応できる。 - クラウド依存の回避
クラウド側のサービス停止やSageMakerエンドポイントの障害があっても、エッジ側で検査業務を継続可能。
採用技術の概要
AWSのマネージドサービス活用
本プロジェクトでは主に以下のAWSサービスを活用しました。
- Amazon SageMaker:異音検知モデルの開発・学習・最適化
- AWS IoT Greengrass:エッジデバイス(Raspberry Pi 5)へのモデルデプロイ・実行・運用管理
- AWS Amplify:フロントエンドとバックエンドを素早く構築・デプロイできるフルマネージドの開発プラットフォーム
- Amazon QuickSight:推論結果の可視化、トレンド分析
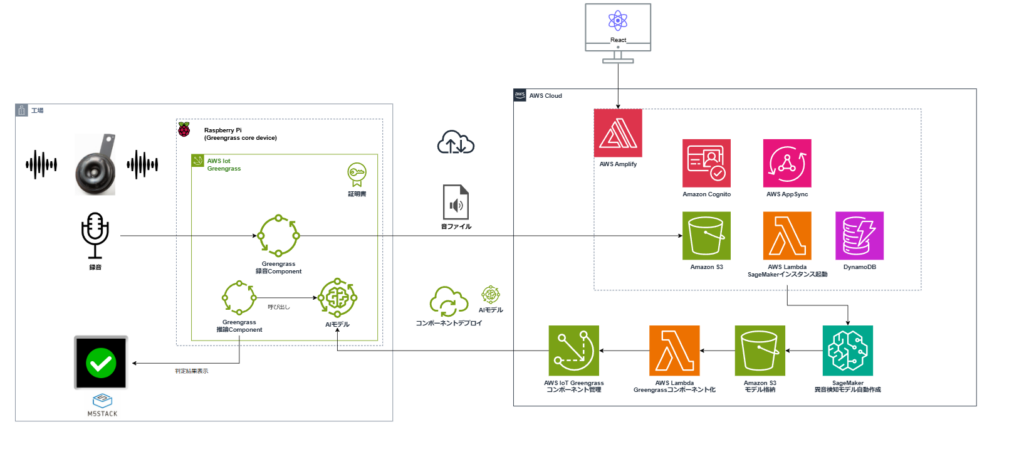
SageMakerで構築した異音検知モデルを、Greengrass経由でエッジに配信することで、クラウドとエッジの両方のメリットを活かしています。
SageMakerはクラウド上で機械学習モデルの開発・学習・最適化を行うプラットフォームであり、Greengrassはエッジデバイス上で機械学習モデルやアプリケーションをデプロイ・実行・管理するためのサービスです。SageMakerで高度な異音検知モデルを構築し、それをGreengrassを通じてエッジに配信することで、クラウドとエッジの利点を両取りできます。
GreengrassはIoTデバイスの運用に必要な機能(デプロイの一元管理、更新、モニタリングなど)を提供するため、各デバイスに個別対応する負担を大幅に減らせます。このようにSageMakerとGreengrassを組み合わせることで、エッジAIの導入を効率的かつスケーラブルに実現できる点が本プロジェクトの狙いです。
エッジデバイスとしては Raspberry Pi 5(ラズパイ5) を採用しました。ラズパイ5は従来機種に比べ飛躍的に性能が向上しており、エッジでディープラーニングモデルをリアルタイム実行するのに十分なスペックを備えているためです。例えば、Raspberry Pi 5のCPU(2.4GHz駆動のArm Cortex-A76 x4コア)は前世代のPi 4より2~5倍高速化しており、TensorFlow Liteを用いた推論性能はGoogle Coral TPUなどの専用AIアクセラレータと同等レベルに達します。
この性能向上により、小型で安価なラズパイ端末上で高度な異常検知モデルを動作させることが可能になりました。またラズパイはコミュニティが豊富で開発リソースが入手しやすいこと、マイクなど周辺デバイス接続性が高いことも利点です。以上の理由から、本プロジェクトでは最新のラズパイ5をエッジ側プラットフォームとして採用し、その上でAWSのGreengrassソフトウェアを稼働させる構成としました。
さらに、AWS Amplifyを活用してWebアプリケーションを構築し、各エッジデバイスの稼働状況や異音検知結果の確認に加え、録音された音声ファイルのダウンロードもブラウザ上で行える仕組みを実現しています。これにより、現場担当者だけでなく、遠隔地からでもシステムの状況を可視化でき、必要に応じてメンテナンスや設定変更をスムーズに行うことが可能になりました。
SageMakerによるオートエンコーダの学習
まず、異音検知に適した機械学習モデルとして オートエンコーダ(Autoencoder) を選択しました。オートエンコーダは入力データそのものを再現するように学習するニューラルネットワークで、通常時(良品の音)のデータパターンを記憶します。異常検知では「正常データのみでモデルを訓練し、得られたモデルで入力データを再構成してみて、その再構成誤差(入力との差分)が大きければ異常と判定する」という手法を取ります。
モデルは正常音でのみ学習しているため、学習済みモデルは正常時の音声を高精度に復元できますが、もし入力に異常な音が含まれていれば復元誤差が大きくなります。この誤差に閾値を設定することで異音の検出が可能になります(閾値は正常データでの平均誤差+αなど適切に設定します)。
オートエンコーダはラベル付きの異常データがほとんど用意できない状況でも教師なし学習でモデル構築できる利点があり、未知の異常にも対応しやすいという特徴があります。不良品が滅多に出ない、今回のような事例にはぴったりです。
本プロジェクトでは音声データとしてホーンの動作音をサンプリングし、周波数特性をモデルが学習できるよう メルスペクトログラム への変換を行いました。具体的にはマイクで取得した音声を一定時間幅(例えば0.2秒間など)で切り出し、短時間フーリエ変換からメル尺度のスペクトログラムを計算し画像のような2次元配列データを入力特徴量としました。
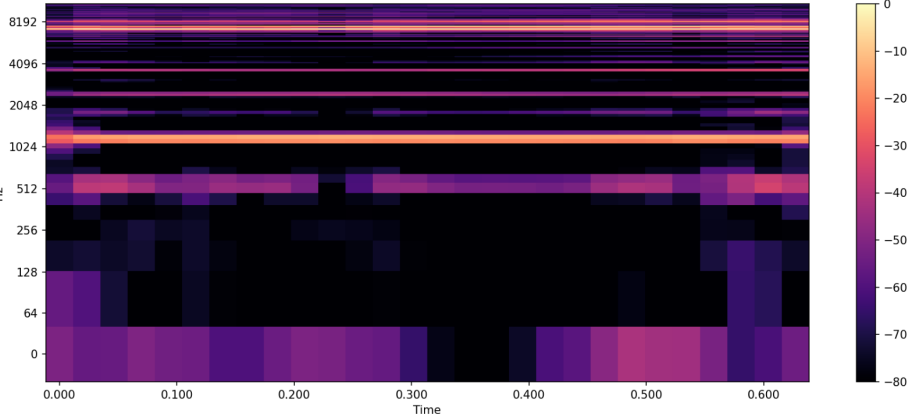
これにより時間と周波数の両方向で異常を捉えることができます。モデルの設計にはTensorFlow Keras を使用し、エンコーダとデコーダから成るシンプルな畳み込みオートエンコーダを実装しました。エンコーダは入力スペクトログラムから低次元の潜在ベクトルを抽出し、デコーダがそこから元のスペクトログラムを再構成します。以下にエンコーダ・デコーダの構成例を示します。
※TensorFlowでオートエンコーダを実装する一般的な方法です。
import tensorflow as tf
from tensorflow import keras
from tensorflow.keras import layers
# エンコーダの定義(入力を潜在ベクトルへ圧縮)
encoder = keras.Sequential([
layers.Input(shape=(128, 128, 1)), # 128x128のスペクトログラム画像を想定
layers.Conv2D(32, kernel_size=3, activation='relu', padding='same'),
layers.MaxPooling2D(pool_size=2), # ダウンサンプリングで次元圧縮
layers.Conv2D(16, kernel_size=3, activation='relu', padding='same'),
layers.MaxPooling2D(pool_size=2),
layers.Flatten(),
layers.Dense(64, activation='relu') # 最終的な潜在ベクトル次元=64
], name="encoder")
# デコーダの定義(潜在ベクトルから元の次元に復元)
decoder = keras.Sequential([
layers.Input(shape=(64,)), # 潜在ベクトル(長さ64)が入力
layers.Dense(32 * 32 * 16, activation='relu'), # 特徴マップを展開
layers.Reshape((32, 32, 16)),
layers.Conv2DTranspose(16, kernel_size=3, activation='relu', padding='same'),
layers.UpSampling2D(size=2), # アップサンプリングで元の解像度へ
layers.Conv2DTranspose(32, kernel_size=3, activation='relu', padding='same'),
layers.UpSampling2D(size=2),
layers.Conv2DTranspose(1, kernel_size=3, activation='sigmoid', padding='same')
], name="decoder")
# オートエンコーダモデルの結合
input_spec = keras.Input(shape=(128, 128, 1))
latent = encoder(input_spec)
reconstructed = decoder(latent)
autoencoder = keras.Model(inputs=input_spec, outputs=reconstructed, name="autoencoder")
autoencoder.compile(optimizer='adam', loss='mse')
print(autoencoder.summary())
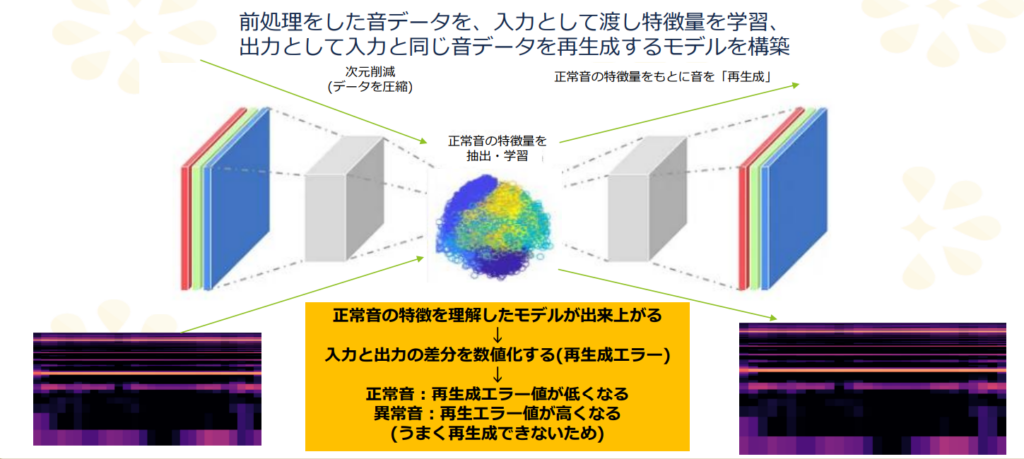
モデルはAWS SageMaker上で学習させました。SageMakerを用いることで、クラウド上のGPUインスタンスを利用したスケーラブルな学習が可能となり、大規模データであっても効率よく訓練できます。開発にはSageMakerのJupyterノートブックを使用し、データの前処理からモデル定義・学習実行までを行いました。データセットとして正常時の音データを大量に収集し、8割を学習用、2割を検証用に分割してモデルに与えました。学習中は検証データに対する再構成誤差の推移をモニタリングし、過学習を防ぐためエポック数やネットワーク容量を調整しました。例えばエンコーダの潜在次元を大きくしすぎると正常データを完全に記憶してしまい異常検知能力が落ちるため、潜在次元や層の数は異常検知の精度とモデルサイズのバランスを考慮して決定しました。
モデル訓練後、検証データおよび想定される異常音データで評価を行いました。異常音データは実際に担当者にご確認いただき「不良」と判定された音を使用しました。
正常音の誤差分布と異常音の誤差分布に明確な差異が生じていることを確認し、適切な閾値を設定しました。評価指標としては、異常検知の再現率・適合率、F1スコアに加え、現場での誤報(false positive)が業務に与える影響も考慮しながら閾値調整を行っています。最終的に、オートエンコーダによる異音検知モデルは正常データに対して低い誤差、異常データに対して高い誤差を示す段階まで調整しました。
運用テスト段階では、検査員が「良品」として判定するも、機械学習モデルが「不良」と判定するケースがありました。工場長に確認をしたところ、「不良」が正しいとわかり、実用上十分な精度で異音を検出できることを確認しました。
AWS Greengrassを活用したデプロイ
クラウド上で学習・評価を終えたモデルは、AWS IoT Greengrassを活用してラズパイ5にデプロイしました。GreengrassはIoTデバイス上で動作するエッジランタイムで、クラウドのAWS IoT Coreと連携してデバイス上でLambda関数やコンテナ、機械学習モデルなどを実行・管理することができます。Greengrassを使うことで、AWS側からエッジデバイスへのソフトウェアデプロイや設定変更、デバイスからクラウドへのメトリクス送信などが容易になります。
Greengrass環境のセットアップ
まずラズパイ5上にGreengrassコアソフトウェアをインストールしました。AWS IoT Core上で当該ラズパイを「IoTデバイス(Thing)」として登録し、証明書を発行してから、ラズパイ上でGreengrass v2のインストーラを実行する手順です。インストール後、ラズパイ5はAWS IoT Greengrass Coreデバイスとしてクラウドとセキュアに接続され、Greengrass経由でデプロイ命令を受け取れる状態になります。
Greengrassをセットアップしたラズパイ5では、クラウド側から「コンポーネント」をデプロイします。Greengrass v2では、各コンポーネントごとに実行するコードや含めるリソース(モデルや依存ライブラリなど)、起動方法を定義したレシピを作成します。今回デプロイする必要があるのは「学習済み異音検知モデル」および「そのモデルを使った推論アプリケーション」の2つです。そこで以下のような構成でコンポーネントを準備しました。
- MLモデル・コンポーネント: SageMakerで学習し最適化したオートエンコーダモデル本体。後述するモデル最適化(コンパイル)を施したモデルファイル群をアーティファクトとして含みます。
- 推論アプリケーション・コンポーネント: マイク入力を監視し、モデル推論を実行して異常を検知するPythonプログラム。必要に応じてPyAudioなど音声処理ライブラリやモデル推論に必要なランタイムを含めます。推論結果をm5stackに送信するロジックも組み込みました。
Greengrassでは上記コンポーネントをそれぞれ作成し、関連する設定(モデルファイルへのパスを環境変数で渡す等)を行った上で、デプロイ命令を受け取ったラズパイ5 (Greengrassコアデバイス) は、該当コンポーネントの実行に必要なファイルをクラウド(S3やGreengrassサービス)からダウンロードし、ローカルでコンポーネントを起動します。
TensorFlow Liteによるモデルの最適化とコンパイル
上記のデプロイ構成を実現するため、事前にSageMaker上でモデルを デバイス向けに最適化 しました。具体的にはTensorFlow Lite(TFLite)形式にコンバートしました。TFLiteはモバイルや組み込みデバイス向けに最適化された軽量推論エンジンであり、モデルをコンパクトにしてデバイス上で高速・省メモリに推論できるよう設計されています。SageMaker上で学習したモデルをSavedModel形式でエクスポートし、TensorFlow Lite Converterを用いて量子化などの最適化込みでTFLiteファイルに変換しました。これにより、後述するRaspberry Pi上でもスムーズにモデルが動作する準備が整いました。
Greengrass経由でのモデルデプロイ
Greengrassコンポーネントの作成が完了したら、Amplifyで作成したWebアプリから、対象デバイス(ラズパイ5)に対しコンポーネントのデプロイを実行します。するとクラウド経由でラズパイ上のGreengrassエージェントに通知が届き、該当するモデルとアプリのアーティファクトが自動的にダウンロード・配置されます。Greengrassは依存関係を解決した上でコンポーネント内のスクリプト(推論アプリ)を起動します。
以上で、クラウドで学習したモデルをエッジ(ラズパイ5)上に配備することができました。次に、実際にラズパイ5上でリアルタイムの異音検知推論を実行し、その仕組みについて解説します。
Raspberry Pi 5上でのリアルタイム推論
デプロイされた異音検知モデルは、ラズパイ5上で常時マイク入力を監視しながらリアルタイム推論を行います。異音を検知した際、本システムでは即座に設置しているM5Stackに判定結果を表示します。
M5 Stackについてはこちら:https://m5stack.com
Greengrass経由でクラウドと連携していることで、デバイスからのフィードバックだけでなく、クラウドからデバイスへの制御も容易になっています。例えば閾値の調整やモデルのアップデートを行いたい場合、AWS IoT Coreのメッセージ経由でGreengrassコンポーネントにコマンドを送り、ランタイム中のパラメータを書き換えることもできます。実運用において、環境音の変化などで閾値調整が必要になるケースがありますが、その際Webアプリ経由でリモートから安全にパラメータ変更できる点は大きなメリットです。また、新しい学習済みモデルをSageMakerで作成した場合も、Greengrassのデプロイ機能で各デバイスにOTA(Over-The-Air)アップデートが可能であり、全デバイスのモデルを一括更新できます。
実践から得られた技術的洞察
実際にシステムを構築し運用する中で得られた知見や直面した課題とその解決策について、いくつか重要なポイントを共有します。
- モデルの軽量化と最適化の重要性: 初期にSageMaker上で構築したモデルは、精度を重視した結果、パラメータ数が多く、ラズパイ上での推論には約2秒を要していました。このままではリアルタイム処理には不十分なため、潜在次元の削減や量子化によるモデル圧縮を実施しました。その結果、推論時間を約1/5(約0.4秒)まで短縮し、異常検知までのレイテンシーを大幅に改善することができました。エッジAIでは限られたリソースの中で動作させる必要があるため、精度を維持しつつモデルを軽量化・最適化することが不可欠であることを改めて実感しました。
- Greengrassデプロイと運用のベストプラクティス: Greengrassを用いたデプロイでは、コンポーネント間の依存関係管理とリソースアクセスの権限設定がポイントでした。推論用のPythonコードからモデルファイルにアクセスするために、レシピ内で適切にパスを指定し権限を付与する必要があり、この設定ミスで当初モデルが呼び出しに失敗→推論できない問題が発生しました。解決策としては、Greengrassコンポーネントレシピの
ComponentDependsOnやローカルリソースの指定を正しく行い、デプロイ前にテスト環境でパスや環境変数が期待通り設定されていることを確認することです。また、本番運用ではSecureTunneling コンポーネントをデプロイし、リモートでssh接続できるようにしました。これにより、これまでは踏み台PCを現地に置き、そこからラズパイに接続していたところが、踏み台PCが不要となったことで運用効率が向上しました。 - エッジデバイス運用管理: 台数が増えていくと各デバイスの状態監視やアップデート管理が課題になります。本システムではGreengrassとAWS IoT CoreのMQTTなどを組み合わせ、デバイスごとの死活監視を実現しました。今後はFleet Provisioningを使用した複数デバイスへの一括プロビジョニングやデプロイにチャレンジしたいと考えています。
- 異常検知システム全体の信頼性: 異音検知は誤検知が多発するとアラーム疲れを招き、検知漏れがあると致命的な故障を見逃す可能性があります。本プロジェクトではこれまでトラストのエンジニアが手動でモデルを作成し、閾値を決定していましたが、前述のモデル評価指標を自動で算出する方式を採用したことで、自動でモデル作成ができるようになりました。また環境音が変化した場合に備え、定期的に正常時データを再収集してモデルをweb画面から再構築することも可能です。
以上の知見から、エッジAIシステムを構築する際には機械学習のモデル精度向上とデバイス運用の両面において綿密なチューニングと管理が必要であることがわかりました。しかし、AWSの包括的なサービス群(SageMaker、Greengrass、IoT Core他)を適切に組み合わせることで、多くの課題は効率的に解決でき、当社のような開発チーム(今回は2名)でも短期間で高度なエッジAIソリューションを実現できました。
まとめと今後の展望
本記事では、AWS SageMakerを用いたTensorFlowオートエンコーダによる異音検知モデルの構築から、AWS IoT Greengrassを介したRaspberry Pi 5へのデプロイ、そしてエッジデバイス上でのリアルタイム推論まで、一連の流れを技術的側面から解説しました。クラウド上での機械学習モデル開発とエッジデバイスへの展開・実行をシームレスに連携させることで、低レイテンシーかつ精度の高い異常検知システムを構築できたことがお分かりいただけたかと思います。特にAWSのマネージドサービスを適切に活用することで、開発効率と運用性を両立できた点は本プロジェクトの大きな成果です。
今後の展望としては、さらに高度な異常検知や追加機能への発展が挙げられます。例えば現在はオートエンコーダによる検知のみですが、将来的には異常音の種類を判別する分類モデルや、異常発生の予兆を捉える時系列予測モデル(例: LSTMや時系列異常検知アルゴリズム)との組み合わせも検討できます。
当社としては、本プロジェクトを通じて得られた知見とプラットフォームを基に、今後もエッジAIソリューションの開発をリードしていきます。AWSを駆使した機械学習基盤の構築から、デバイスへの実装・運用まで一貫して手掛ける技術力は当社の強みであり、これを活かしてお客様のDX(デジタルトランスフォーメーション)を支えるサービスを提供して参ります。本記事で紹介した取り組みが、エッジAI導入を検討している技術者の方々やプロジェクトの参考になれば幸いです。


