AWS re:Invent 2025 現地レポート Day1

はじめに
本記事ではAWS re:Invent 2025のDay1の現地の様子について、参加したセッションの内容や最新情報をご紹介します。
1日のスケジュール
12/1のDay1では4つのセッションに参加しました。今年はSaaS × 生成AI(Agent)のセッションを中心に回っています。
まずは6時ごろ起床し一日が始まりました。今年は時差ぼけ対策成功!5時間一度も起きずに寝ることができました。

メイン会場のVenetianでバッジピックアップ。今年は空港では受け取らないように添乗員の方から伝えられていました。


意識していないですが、程よく顔がピンボケになっています笑
1つ目のセッションは8:30からだったので、少しだけ会場内を散歩しました。


参加セッション 1: SAS304 | Transforming from SaaS to multi-tenant agentic SaaS
まずは1つめ。SaaSにAIエージェント機能を追加する方法についてのセッションでした。登壇者はお二人ともPrincipal Solutions Architect。肩書がかっこいいですね。
こちらのセッションの目的としては、新規でマルチテナントエージェントを作成ではなく、既存のSaaS→Agentic SaaSにどのように移行していくか?に重点が置かれていました。

Agentic AIとは「自律的に動作するAIシステム」のことですが、セッションで強調されていたのは「人間の作業を効率化する」という点でした。規制の厳しい業界では完全自律は難しいので、あくまでサポート役として使うのが現実的とのこと。

SaaSでAgentを活用するパターンとして以下が紹介されました:
- 既存アプリをMCPやAPIでラップして、外部のエージェントから使えるようにする
- チャットボットのように人間が直接操作するエージェントを提供
- エージェント同士が通信する形態、A2AやMCP関連(今後増えていく領域)
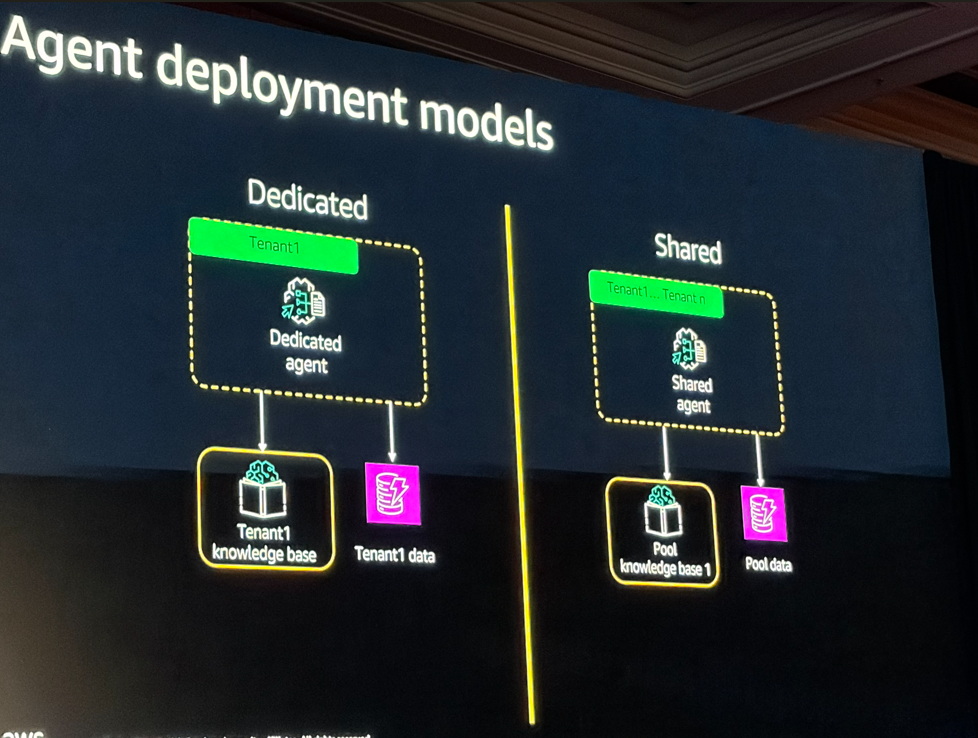
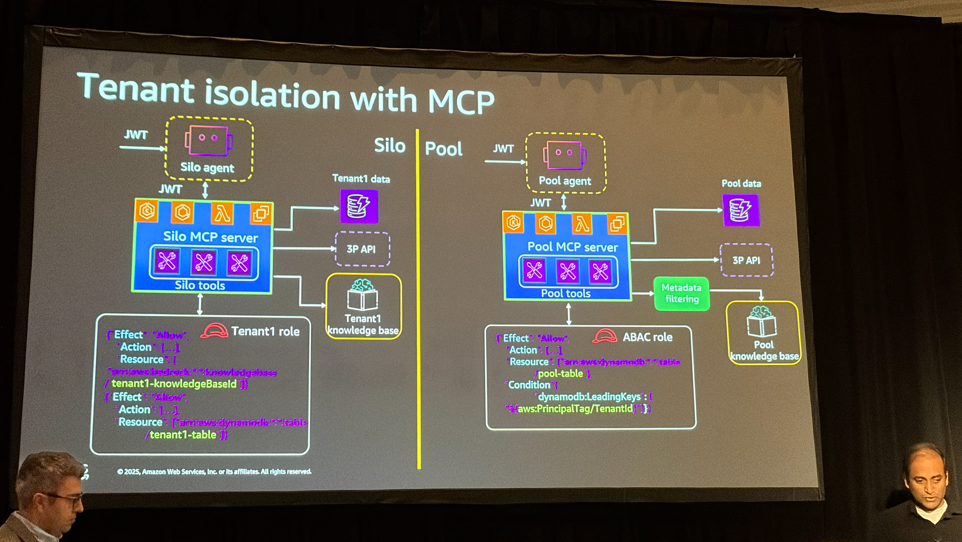
マルチテナントでのデプロイ方法としては、テナントごとに専用リソースを持つ「Silo」と、リソースを共有する「Pool」、一部を専用、一部を共有にするハイブリッドBridgeモデルの3パターンがあります。ここではSiloとPoolに限定して話されていました。
Poolの方がコスト効率は良いですが、テナント分離の実装が複雑になります。
また、オブザーバビリティの話も出てきました。多くの監視ツールではテナントIDが標準でサポートされていないので、カスタムメトリクスを作る必要があるとのこと。(このように私は理解しましたが、実際に手を動かして検証します。)
参加セッション 2: SAS306 | Building multi-tenant RAG and MCP servers
2つめはRAGとMCPサーバーのマルチテナント化についてのセッションでした。
このセッションはchalk talkと呼ばれる、従来の登壇者→セッション参加者という一方通行の進め方ではなく、セッションを進めながら、参加者がその場で質問をするという方式でした。このセッションは昨年同様YouTubeにアーカイブされません。現地参加だからこそ見られる、まさに醍醐味と言える内容です。セッション自体はかなり盛り上がり、参加者の熱量が凄かったこともあって、発表がなかなか進みませんでした笑

デモシナリオ
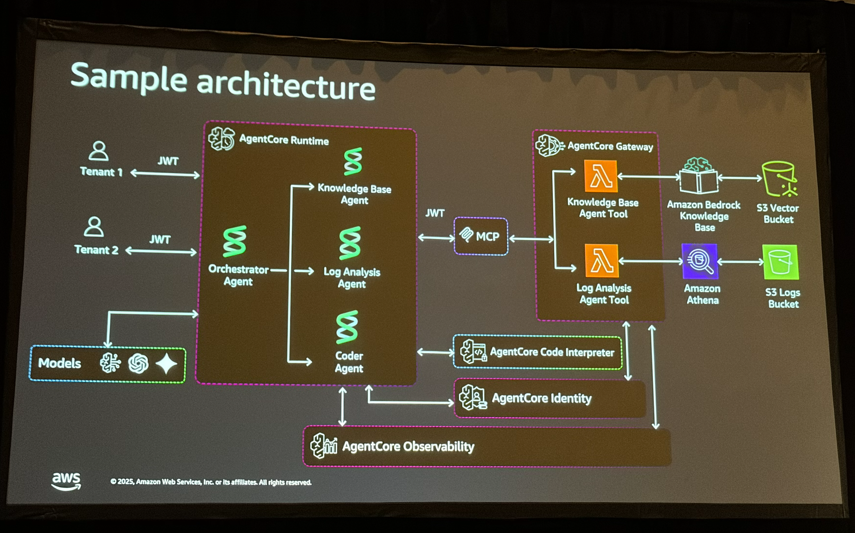
説明用のデモとして「SRE向けエージェント」が使われていました。障害が発生したときに、ドキュメントを検索するエージェント、ログを見るエージェント、修復アクションを実行するエージェントの3つが連携する構成です。
マルチテナントRAG
マルチテナントでRAGを構築する際の最大の課題はテナント分離です。
- Siloモデル: テナントごとに専用のKnowledge Baseを持つ。シンプルだけどコストが高い
- Poolモデル: 共有のKnowledge Baseを使い、メタデータフィルターでテナントを絞る。コスト効率は良いけど実装が複雑
- Bridgeモデル: 一部を専用、一部を共有にするハイブリッド
Poolモデルでは、データ取り込み時にテナントIDをメタデータとして付けておき、検索時にフィルターをかけます。この方法ならコストを抑えつつテナント分離ができます。
Agent Coreの紹介
このセッションでもAgent Coreが紹介されました。特にAgent Core Gatewayは「MCP as a Service」として動くので、MCPサーバーの構築・運用がかなり楽になりそうです。
上記に加えて、MCPを使ってテナント分離をする方法なども紹介されていました。
参加セッション 3: SAS407 | Building multi-tenant SaaS agents with Amazon Bedrock AgentCore
このセッションは400レベルで、実際のコードを見ながらの解説でした。
冒頭でワークショップとGitHubのコードも紹介されていたので、後で試してみたいです。
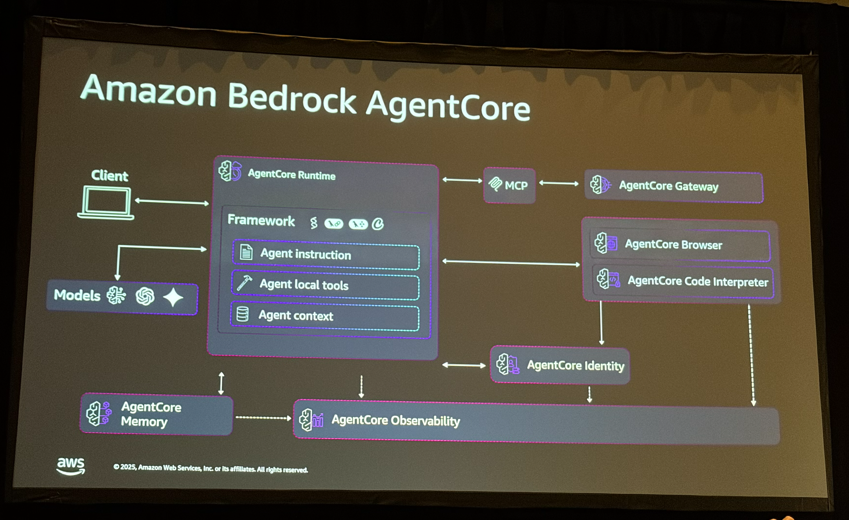
Amazon Bedrock Agent Coreは以下のコンポーネントで構成されています:
- Agent Core Runtime: エージェントを動かす場所
- Agent Core Gateway: ツールをMCPで公開(MCP as a Serviceと言っていました)
- Agent Core Identity: 認証・認可
- Agent Core Memory: 短期記憶と長期記憶
- Agent Core Observability: 監視
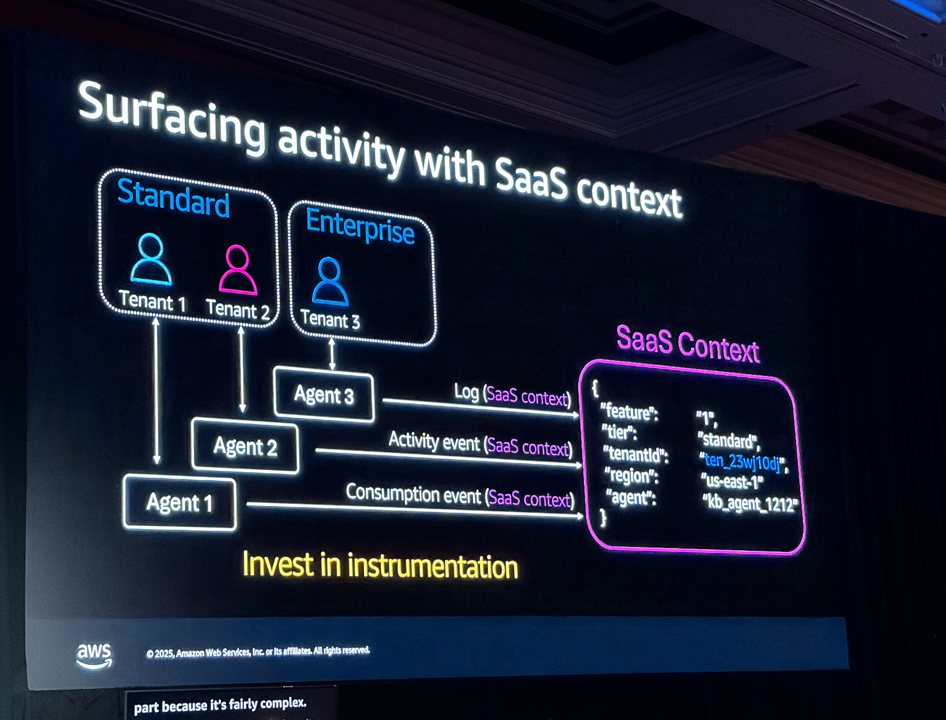
SaaSでよくある5つの課題(テナントオンボーディング、認証、データ分割、テナント分離、監視)をAgent Coreでどう解決するかという流れで説明がありました。
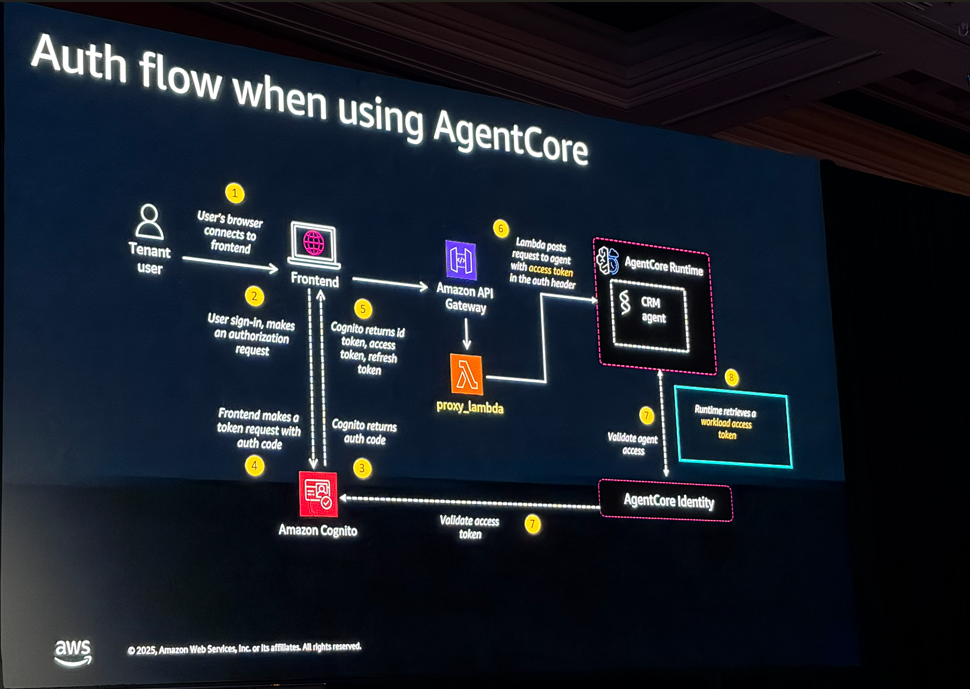
認証まわり
JWTトークンにテナントIDやユーザーIDを入れて、それをAgent Core全体で使い回す設計です。外部APIを叩く際のOAuthやAPIキーの管理もAgent Core Identityで抽象化できるとのこと。アノテーション1つでアクセストークンが取れるのは便利そうでした。
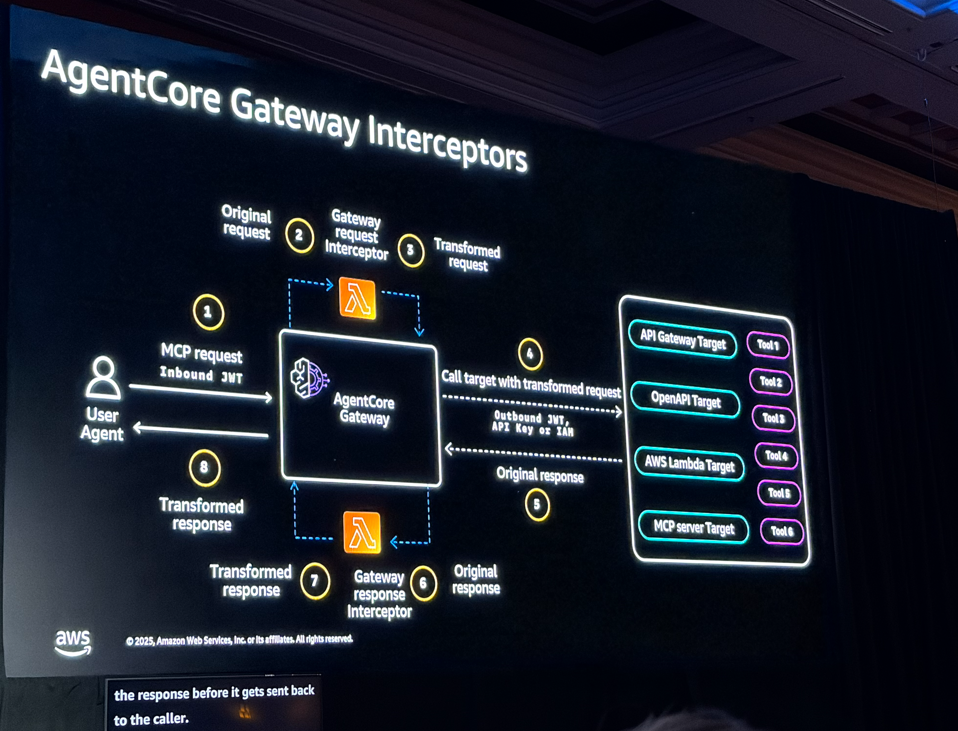
またつい先日GAされたAgentCore Gateway Interceptorsについても、かなり詳細に解説がされました。
流石Lebel400のセッションということで、前提知識がかなりないと厳しいですね。たまたま機内でこの内容の動画を見ていたので理解できてよかったです。
コスト計算
エージェントで一番コストがかかるのはLLMの推論なので、テナントごとにトークン数を計測してCloudWatchに送り、Cost and Usage Reportと組み合わせてコストを算出する方法が紹介されていました。QuickSightで可視化すれば、テナント別のコストが見えるようになります。
実際にSaaSでエージェントを提供するとなると、この辺りの仕組みは必須になりそうですね。
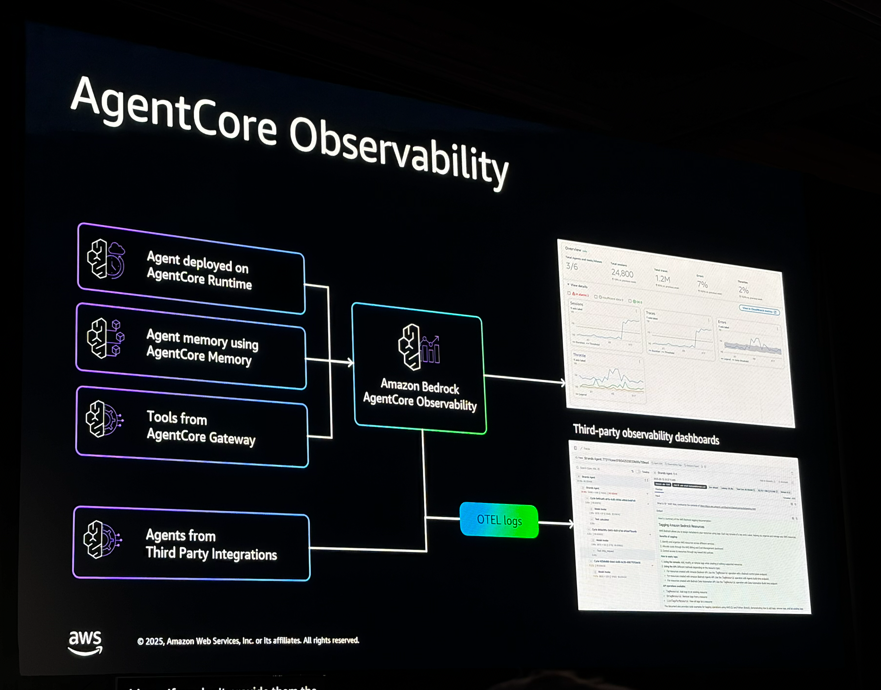
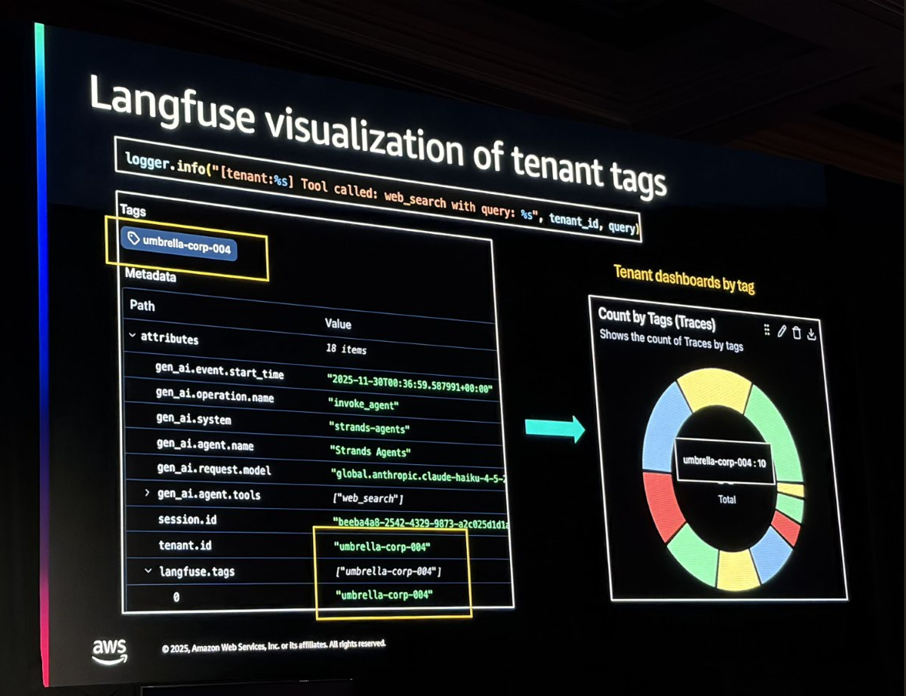
Langfuseを使ったテナントタグによる集計はかなり参考になりました。
参加セッション 4: INV204 | Build and scale AI: from reliable agents to transformative systems
最後はInnovation Talkです。こちらはLevel 200なのでエンジニアだけでなく、経営者なども参加されるようなビジネス的な話が多かったです。
信頼性の話
AWSのAaron氏から、AIエージェントの信頼性を構築するための4つの柱が紹介されました:
- Reliable: AWSインフラの信頼性
- Transparent: オブザーバビリティで中身を見える化
- Safe: ガバナンスとガードレール
- Easy: StrandsやAgent Coreで開発を簡単に
Gartnerによると「2027年末までに40%以上のAgentic AIプロジェクトがキャンセルされる」という予測があるそうです。理由は、開発環境では動いていたのに本番でループしたり、ログがなくてデバッグできなかったり。これはモデルの問題ではなく基盤の問題とのこと。
Agent Coreのデモ
AWSのMark Berger氏がAgent Coreのデモを見せてくれました。re:Inventのセッション選択を手伝うエージェントに、メモリ機能を追加するというもの。数クリックと数行のコードで「朝のセッションが好き」「AIとDBに興味がある」といった好みを記憶できるようになりました。
Strandsというオープンソースのフレームワークも紹介されていて、ローンチ以来500万回近くダウンロードされているそうです。
Sendbirdの事例
SendbirdのCEO、John Kim氏が登壇。月間70億件の会話を処理しているコミュニケーションプラットフォームです。
Delight AIというカスタマーサービス向けAIエージェントの事例が紹介されました。
- BJ’s(米国の小売): AIエージェント「Bea」を導入。平均注文額が20%増加、AIとやり取りしたユーザーは6倍の支出!
- Norse Atlantic Airways: AIコンシェルジュ「Freya」で、顧客の好みを記憶してパーソナライズ
AIをコスト削減ではなく売上向上の手段として使っているのが面白いですね。
Lyftの事例
LyftのEVP、Jason Vogerman氏が登壇。カスタマーサポートのAI化について発表しました。
Lyftにはドライバーとライダーという2種類の顧客がいて、どちらも信頼がないとサービスが成り立ちません。課題として「45分かけて$2のキャンセル料を追いかけた」「ヘルプを求めるのも面倒」という声があったそうです。
AIを導入した結果:
- 解決時間: 16分(最大3日)→ 3分以下
- AIで解決された割合: 0% → 55%
パートナーはAnthropicのClaudeとAWS。GenAI Innovation Centerと一緒に開発したとのこと。
導入プロセスとして7ステップが紹介されていました:
- 経営層の合意(コスト削減ではなく「変革」として)
- 2-3の高インパクトなユースケースを選ぶ
- データの準備
- エージェントの設計(ガードレール含む)
- テスト(自動テスト + 人間のレビュー)
- パイロット(5-15%のトラフィック)
- スケール
最短21日で本番稼働したケースもあるそうです。
学んだ教訓として「内部テストでは見えないことがある」「評価指標は完璧でなくていい、まず始める」「AIのタイムラインは予測困難なので柔軟に」という話がありました。実際に運用している会社の話は参考になりますし、これくらい分かりやすく数字で結果を出すことがやはり大切だと再認識しました。
まとめ
以上、「AWS re:Invent 2025 現地レポート Day1」でした!
Day1はSaaS × AIエージェントのセッションを中心に回りました。印象に残ったポイントは以下です:
技術面
- Agent Coreはやはり今後のプロジェクトでは必須になりそう。Runtime、Gateway、Identity、Memory、Observabilityが揃っているので、マルチテナントエージェント実現しやすい道具を用意してくれていると感じました。
- マルチテナントではABACとメタデータフィルターでテナント分離。ここは事前に調査していた知識と一致していたので、答え合わせが出来てほっとしました。
- テナント別のLLMコスト計算が重要。これもObservabilityを活用するが、単純なコスト算出のためだけではなく、その情報をどのように活用するかが最も大切だとスピーカーは繰り返していました。
ワークショップのコードがGitHubで公開されているので、後で試してみたいと思います。
ビジネス面
- Lyftは16分→3分、55%がAI解決という成果
- SendbirdのBJ’s事例では、AIとやり取りしたユーザーが6倍の支出
- AIは「コスト削減」だけでなく「売上向上」にも使える
→このようなAI導入が分かりやすく成果として出せるように、今後は意識すべきだと考えさせられました。
明日のDay2は、本日3つめのセッション内容を実際にハンズオンで体験する予定です。本日は大量のインプットでしたが、明日はインプット&アウトプットを大量にしていきます!
これらの内容も投稿しますので、お楽しみに!


