AWS re:Invent 2025 現地レポート Day2

はじめに
本記事ではAWS re:Invent 2025のDay2の現地の様子について、参加したセッションの内容や最新情報をご紹介します。
1日のスケジュール
12/2(火)のDay2では、1つのKeynote、1つのハンズオンセッションに参加しました。また、Expoにも立ち寄りました。
| 時間 | 内容 |
|---|---|
| 8:00-10:30 | Keynote: Matt Garman (AWS CEO) |
| 12:30-14:30 | SAS403-R1: Hands-on multi-tenant agents |
| 15:30-16:00 | Expo散策 |
Keynote: Matt Garman (AWS CEO)
Day2の朝はAWS CEOのMatt GarmanによるKeynoteからスタートしました。
昨年同様6時台に並んでもこれだけ列が出来ていました。re:Inventのメインイベントとも言えるような、大型アップデートが多数発表されるからでしょうか。


会場に入ると、こちらも昨年同様、DJが曲をかけていて徐々に会場が盛り上がり始めていました。

今年のKeynoteでは、生成AI関連の発表、特にAgent関連のLaunchが目白押しでした!


Mattさんはかなり遠かったです。
以下、発表された順番ではないですが、私の印象に残っているアップデートをピックアップしてご紹介します。
詳細はこちら(re:Invent期間中のUpdateをまとめてくれています): https://aws.amazon.com/jp/blogs/aws/top-announcements-of-aws-reinvent-2025/
Amazon Nova 2シリーズ – 次世代基盤モデル
今回のKeynoteで最も印象に残っているのが、Amazon Novaの次世代モデル「Amazon Nova 2」シリーズの発表です。ちょうど1年前にNovaシリーズが発表されてからアップデートが無かったので、正直来るとは思っていましたが、新規モデルが多数発表されたのは驚きでした。

| モデル | 特徴 | 提供状況 |
|---|---|---|
| Nova 2 Lite | 高速・低コストの推論モデル。100万トークンのコンテキストウィンドウ、拡張思考機能搭載 | GA |
| Nova 2 Pro | 最も知的な推論モデル。高度に複雑なワークロード向け | プレビュー |
| Nova 2 Sonic | 音声対音声モデル。リアルタイムで人間らしい会話型AI | GA |
| Nova 2 Omni | 業界初のマルチモーダル推論+画像生成モデル | プレビュー |
特にNova 2 Liteは、拡張思考(Extended Thinking)機能を搭載しており、ステップバイステップの推論やタスク分解が可能です。また、100万トークンという巨大なコンテキストウィンドウと、コードインタープリターやWeb groundingなどのビルトインツールも備えています。
Nova 2 Proは「最も知的な推論モデル」として位置づけられ、高度に複雑なワークロード向けに設計されています。本日よりプレビュー提供が開始されました。
Nova 2 Sonicは会話型AIに特化した音声対音声モデルで、ポルトガル語やヒンディー語など多言語に対応。日本語対応はされるのでしょうか?
Nova 2 Omniは業界初の「マルチモーダル推論+画像生成」を1つのモデルで実現。テキスト、画像、動画、音声を入力として受け付け、テキストと画像の両方を出力できます。
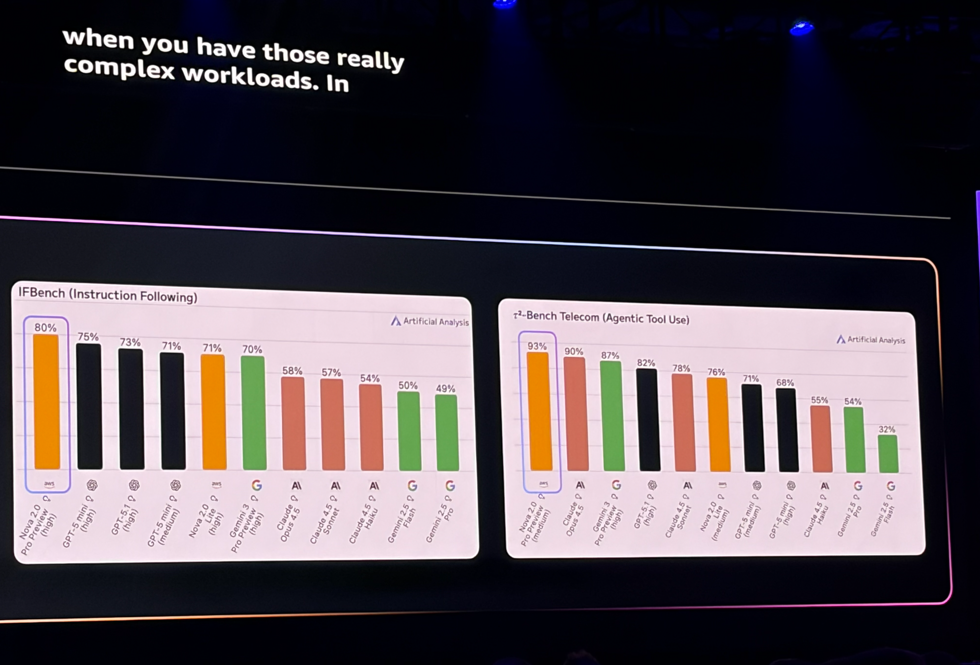
Nova 2.0 Proは一部のベンチマークでClaude Opus 4.5を上回る性能があるらしいです。こちらはプレビューですが、今後試してみようと思います。
Amazon Nova Forge & Nova 2 Omni
Novaファミリーに追加で、カスタマイズとマルチモーダルの新サービスも発表されました:
Amazon Nova Forge

- 組織がNovaモデルのトレーニングにアクセスし、カスタムフロンティアモデルを構築可能
- ドメイン専門知識を深く埋め込んだモデルを、従来のコスト・計算資源・時間の障壁なく構築できる。
- RAGでのチューニングでは精度は出ないが、ファインチューニングはコストと時間がかかり採用できないようなケースに合うようです。もしかしたら将来的に使うことになるかも??
Amazon Nova 2 Omni(プレビュー)

・マーケティングコンテンツ作成、カスタマーサポート、ドキュメント理解など幅広いユースケースに対応
・業界初の「推論+画像生成」を1つのモデルで実現するマルチモーダルモデル
・テキスト、画像、動画、音声を入力として受け付け、テキストと画像の両方を出力可能
ゲスト登壇: ソニーグループ 小寺剛 CDO


Keynoteの中盤には、ソニーグループの小寺剛 執行役 CDO(最高デジタル責任者) が登壇しました。ソニーがAWSと連携してエンタープライズAI基盤とエンゲージメントプラットフォームを構築していることが発表されました。PS5がAWS上で構築されているのは初めてて知りました。
主な発表内容:
1. Amazon Bedrock AgentCoreの全社展開
- グループ全社でAIエージェント機能をセキュアに展開
- 社内エンタープライズAI基盤で1日あたり15万件の推論リクエストを処理
- 今後数年で300倍以上に成長する見込み
2. Amazon Nova Forgeの活用
- 社内ドキュメント評価・審査プロセスの効率が従来比約100倍に向上
- 多様な事業と業務推進に向けた最先端AIを構築
3. Sony Data Ocean(データ利活用基盤)
- グループ各社が保有する500種類以上のデータセットを連携
- 760テラバイトに及ぶデータ処理
- Amazon SageMakerを活用したAIインサイト
4. エンゲージメントプラットフォーム
- PlayStationのオンラインサービスのコア機能を活用
- ゲーム、音楽、映画、アニメなど多様な事業でファンとクリエイターをつなぐ
小寺CDOは「AWSとの長年のパートナーシップを通じて、データとAIの力を最大限に活用して、ファンとクリエイターの間に新たな絆を築くことができるようになりました」と述べていました。
エンタープライズ規模でのAIエージェント展開は、まさにトラストでも参考にしたいユースケースですね。特にBedrock AgentCoreを使ったセキュアなAIエージェント展開は、今後検証、確実に習得しないといけない技術だと思います。
re:Inventのスピーカーとして、日本の企業が登壇しているのは嬉しく思いました。
Amazon S3 Vectors(GA)

私的に待ち望んでいた、しばらくプレビュー&東京リージョン非対応だった「Amazon S3 Vectors」が一般提供(GA)&東京リージョンでも使用可能になりました!これはプロジェクトにすぐに活きるので、嬉しかったです。
主な特徴:
- 1インデックスあたり最大20億ベクトル(プレビュー時の40倍!)
- 100msのクエリレイテンシー
- 専門データベースと比較して最大90%コスト削減
- 14のAWSリージョンで利用可能
これまでベクトルデータベースといえばOpenSearch、Pinecone、pgvectorなどを使う必要がありましたが、S3に直接ベクトルを保存できるようになることで、RAGアプリケーションのアーキテクチャがよりシンプルになります。午後のハンズオンでもS3 Vectorsが使われており、実際に手を動かして体験できました。
Amazon Bedrock AgentCore 新機能


午後のハンズオンで使用したAmazon Bedrock AgentCoreにも新機能が追加されました:
- Policy in AgentCore: エージェントのアクションに対するきめ細かい境界設定
- AgentCore Evaluations: 正確性、有用性、安全性などの品質監視
- Episodic Memory: 経験ベースの学習機能
- 双方向ストリーミング: より自然な会話体験
これらの機能により、信頼性の高いAIエージェントを本番環境にデプロイしやすくなります。
その他のAI関連発表
- Amazon Bedrockに18の新モデル追加: Mistral Large 3、Ministral 3など
- Amazon OpenSearch Service: GPU加速と自動最適化でベクトルDBパフォーマンスが10倍向上、コスト1/4
- AWS AI Factories: データセンターにAWSのAIインフラをデプロイ可能に
- AgentCore新機能: エージェントの品質監視・ポリシー制御で本番運用が現実的に
トラストでの活用可能性
Keynoteで発表された内容の中で、特にトラストでの活用が期待できるのは:
- Nova 2 Lite: 拡張思考機能と100万トークンのコンテキストで、複雑な業務タスクを処理
- Nova Act: ブラウザベースの業務自動化に活用できそう
- S3 Vectors(GA): RAGシステムのベクトルストレージコストを大幅削減
- AgentCore新機能: エージェントの品質監視・ポリシー制御で本番運用が現実的に
今後、これらの新サービスについて検証を行っていきたいと思います。
【参考】Top announcements of AWS re:Invent 2025
参加セッション: SAS403-R1 | Hands-on multi-tenant agents: Inside tenant-aware agentic systems

今回参加したのは「Hands-on multi-tenant agents: Inside tenant-aware agentic systems」というハンズオンセッションです。このセッションでは、マルチテナント環境でのAIエージェントシステムの構築方法を実際に手を動かしながら学びました。
ワークショップの概要
このワークショップでは、以下の技術・サービスを使用してマルチテナント・マルチエージェントアーキテクチャを構築しました。
- Amazon Bedrock AgentCore: エージェントのランタイム、ゲートウェイ、オブザーバビリティを提供
- Amazon Bedrock Knowledge Base: テナント別のRAGシステムを構築
- Strands Agent Framework: エージェントの実装フレームワーク

Lab 1: マルチテナント・マルチエージェントアーキテクチャの構築
シンプルなRAGシステムからスタート
最初は、Amazon Bedrock Knowledge Baseを使用したシンプルなマルチテナントRAGシステムを構築しました。
ポイントはメタデータフィルタリングです。テナントごとのデータをS3バケットにアップロードする際に、テナントIDをメタデータとしてタグ付けします。これにより、クエリ時にSQLのWHERE句のようにテナント固有のデータのみを取得できます。
# メタデータファイルの例
{
"metadataAttributes": {
"tenant_id": "tenant1"
}
}
マルチエージェントシステムへの進化
RAGシステムだけでは静的なワークフローになってしまうため、次にLLMの計画・推論能力を活用したマルチエージェントシステムへと進化させました。
構築したエージェント構成は以下の通りです:
| エージェント | 役割 |
|---|---|
| Orchestrator Agent | 全体を統括し、サブエージェントを呼び出す |
| Knowledge Base Agent | RAGシステムから既存の解決策を検索 |
| Log Analysis Agent | テナント固有のログを分析し、根本原因を特定 |
| Coder Agent | コード修正を生成・テスト |
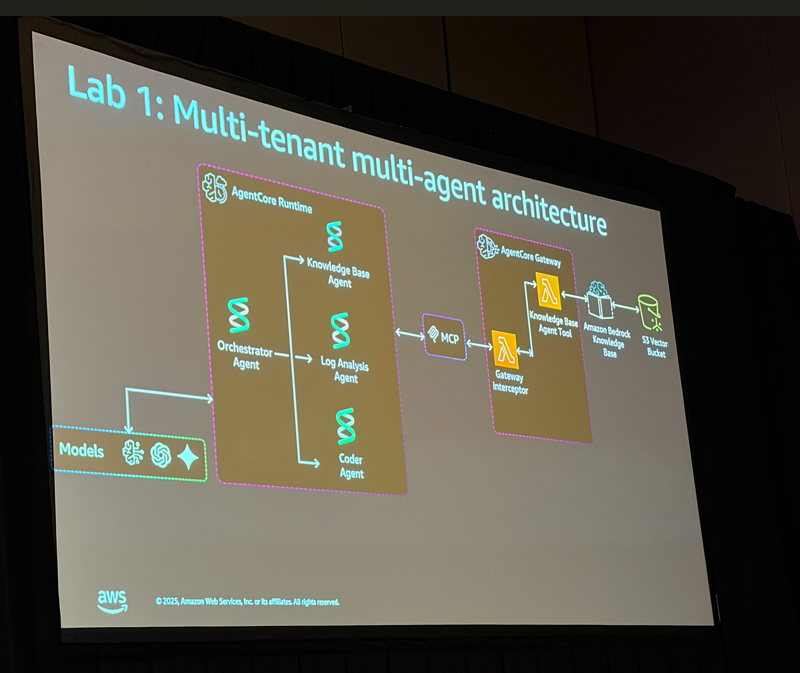
処理の流れとしては:
- ユーザーからの問い合わせをOrchestrator Agentが受け取る
- まずKnowledge Base Agentで既存の解決策を検索
- 見つからない場合はLog Analysis Agentでログを分析
- 問題の根本原因が判明したらCoder Agentでコード修正を生成・テスト
- 解決策をユーザーに返却
これはいわゆるSupervisor(オーケストレーター)パターンと呼ばれるマルチエージェントアーキテクチャです。
Lab 2: テナント分離の実装
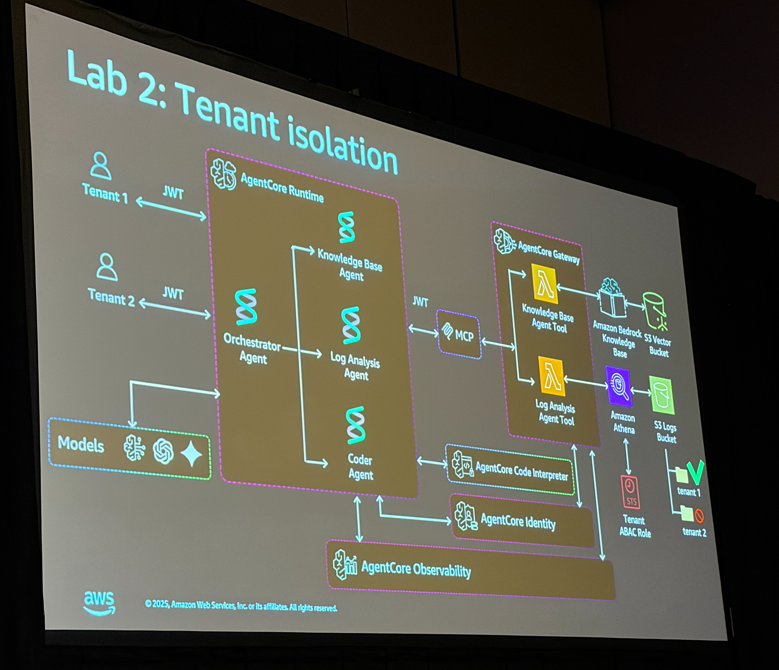
Lab 2では、マルチテナント環境におけるテナント分離(Tenant Isolation) の実装を学びました。
なぜテナント分離が重要か?
エージェント自体はマルチテナンシーを認識していません。つまり、適切な制御がないと、あるテナントのデータに別のテナントがアクセスできてしまう可能性があります。
ワークショップでは、意図的にバグを仕込んで(tenant2のIDをハードコーディング)、tenant1のユーザーがtenant2のログにアクセスできてしまう状況を再現しました。
ABAC(属性ベースアクセス制御)による解決
この問題を解決するためにABAC(Attribute-Based Access Control) を導入しました。
ABACでは、IAMポリシーにテナントIDを動的に注入することで、インフラストラクチャレベルでテナント分離を強制します。
// IAMポリシーの例
{
"Effect": "Allow",
"Action": ["s3:GetObject"],
"Resource": "arn:aws:s3:::logs-bucket/${aws:PrincipalTag/tenant_id}/*"
}
これにより、コードにバグがあっても、IAMレベルでクロステナントアクセスがブロックされます。実際にABACを有効化した後、tenant1でtenant2のリソースにアクセスしようとすると「PERMISSION_DENIED」エラーが発生することを確認しました。
Lab 3: テナントごとのコスト計算
最後のLabでは、テナントごとのコスト帰属(Cost Attribution) モデルを構築しました。
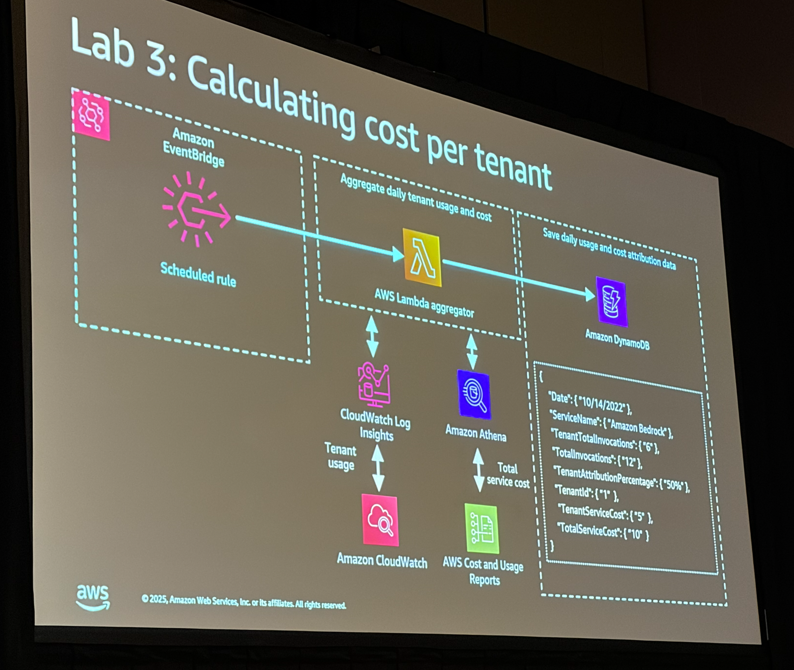
プールモデル(共有リソース)では、誰がどれだけリソースを使用したかを把握するのが難しいですが、以下の仕組みで実現しています:
- Strands Agentのテレメトリ機能でトークン使用量を取得
- Amazon CloudWatchにテナントID付きでログを記録
- Amazon EventBridgeでスケジュール実行
- AWS Lambdaでメトリクスを集計
- Amazon AthenaでAWSコスト・使用レポートをクエリ
- Amazon DynamoDBにテナントごとのコストを保存
# トークン使用量の記録例
record_metric(tenant_id, "ModelInvocationInputTokens", "Count", input_tokens, agent_name)
record_metric(tenant_id, "ModelInvocationOutputTokens", "Count", output_tokens, agent_name)
トラストでの活用可能性
このワークショップで学んだ内容は、トラストでのマルチテナントSaaSアプリケーション開発に非常に参考になりそうです。
特に以下のポイントが印象的でした:
- SaaS Builder Toolkit(SBT): CDKでSaaSアーキテクチャを構築する際のベストプラクティスが詰まっている
- Amazon Bedrock AgentCore: エージェントのデプロイ・運用を簡素化できる新しいサービス
- ABACによるテナント分離: コードのバグがあってもインフラレベルで保護できる安心感
- Gateway Interceptor: 先週リリースされた新機能で、よりきめ細かいアクセス制御が可能に
今後、社内でマルチテナントのAIエージェントシステムを構築する際には、このアーキテクチャパターンを参考に検証を行いたいと思います。
内容としては、昨日の座学からの実践だったので、とてもスムーズに理解出来ました。しっかりとこの知識をまずは社内に還元したいと思います。
Walk-upチャレンジ
ハンズオン終了後、Walk-up(当日枠)で別のハンズオン(こちらはマルチエージェントに対してRAGにフォーカスした内容)にも参加しようと思い、30分ほど並んでみました…が、残念ながら定員に達してしまい入れませんでした。周りの人と話した感じだと、予約開始から5分で満席になっていたようです。
re:Inventあるあるですね。人気セッションは事前予約必須です!
Expo散策

気を取り直してExpo会場へ。各社のブースを回り、ステッカーやSwagをゲットしました!

Expoは様々なAWSパートナーやサービスの展示があり、ユーモア溢れる展示が多かったです。

“リアル”S3バケットがあったので思わず写真を撮ってしまいました笑
他にはこんなものも。
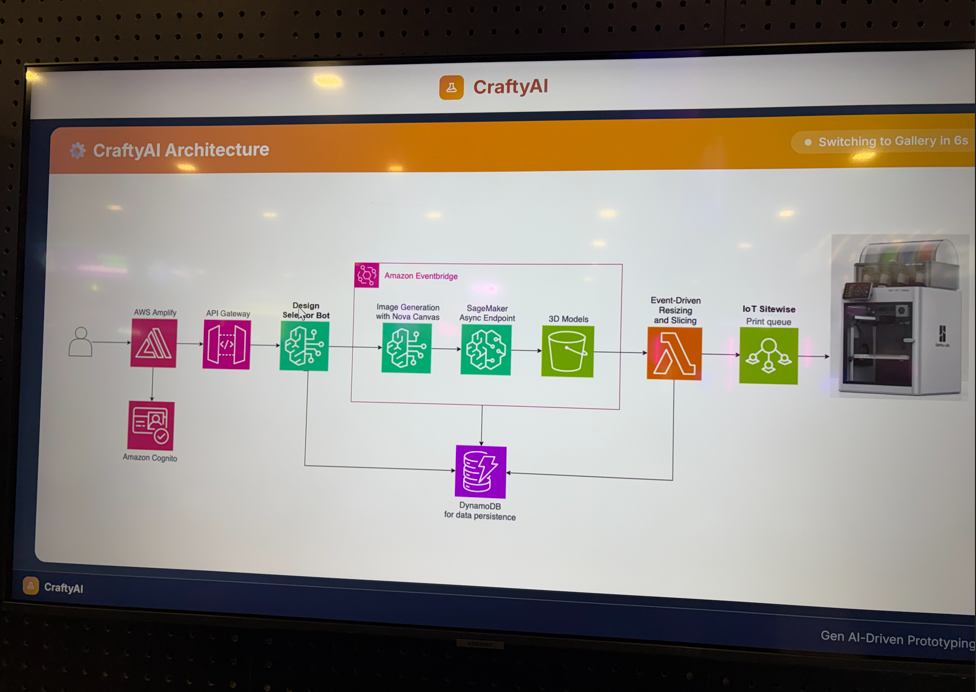
Amplifyを使って3Dプリンターでメダルを作成していました。
こちらも物欲が刺激されるので少しだけ見て退散しました笑


まとめ
以上、「AWS re:Invent 2025 現地レポート Day2」でした!
Day2のハイライトは何といってもマルチテナント・マルチエージェントのハンズオンです。実際に手を動かしながら、以下を学ぶことができました:
- マルチテナントRAGシステムの構築方法
- Supervisor パターンによるマルチエージェントアーキテクチャ
- ABACを使用したテナント分離の重要性
- テナントごとのコスト計算モデル
特にAmazon Bedrock AgentCoreは、エージェント開発を大幅に効率化してくれそうなサービスで、今後の活用が楽しみです。
次回Day3もお楽しみに!


