AWS re:Invent 2025 現地レポート Day3

はじめに
本記事ではAWS re:Invent 2025のDay3の現地の様子について、参加したセッションの内容や最新情報をご紹介します。
1日のスケジュール
| 時間 | 内容 |
|---|---|
| 11:30 AM – 12:30 PM | STG363-R: From prototype to production: Scaling agents with Amazon S3 Vectors(Chalk talk) |
| 13:30-14:30 | AIM3324: Amazon Nova 2 Omni: A new frontier in multimodal AI |
| 15:30-17:30 | SAS302: SaaS Anywhere meets GenAI(ハンズオン) |
12/3(水)のDay3では、3つのセッションに参加しました。今日もSaaS × 生成AIを中心に、新発表のAmazon Nova 2やS3 Vectorsについて深掘りしてきました!
今回は今年初めてのMandaley Bayという会場でのセッションが多かったです。私が宿泊しているホテルからはかなり時間がかかるので、Keynoteは朝食中にAWS Eventsアプリで視聴しました。
会場までの道中




こちらの建物はホテルで、会場はこの横にあります。

会場から撮影した写真です。遠くには山が見えます。
参加セッション 1: STG363-R | From prototype to production: Scaling agents with Amazon S3 Vectors


1つめのセッションは、Amazon S3 Vectorsを使ったエージェントのスケーリングについてです。S3 Vectorsは今年7月にプレビューとして発表され、今回のre:Inventで一般提供(GA)が発表されました。登壇者はS3チームのエンジニアでした。
なぜエージェントにベクトルストレージが必要なのか
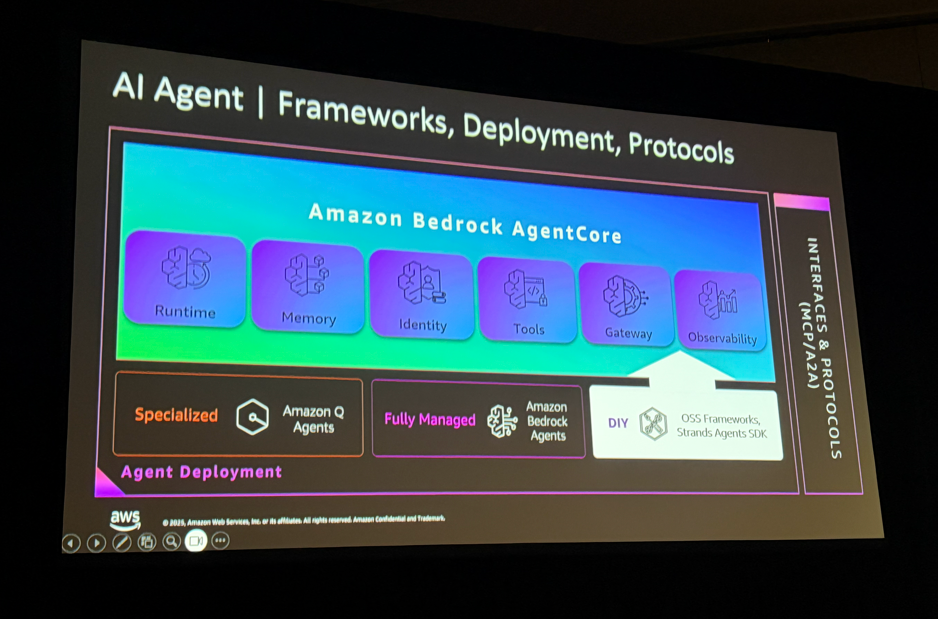
セッションの冒頭で、スピーカーがこんなことを言っていました。
「多くの組織はペタバイト、エクサバイトのデータを持っている。でも、ただ保存してお金を払っているだけじゃないですか?」
確かに、s3はこれまで”storage”として使われてきました。ただ今後エージェントに必要なのは単なるデータではなく、メモリ、コンテキスト、学習、コラボレーション。眠っているアーカイブデータを「アクティブなメモリ」に変えることで、エージェントが過去の情報を活用できるようになる、という話でした。これはなるほど、と思いました。
AIエージェントのフレームワーク全体像も紹介されていました。Strands AgentsやLangChainなどのフレームワークがあり、その上でMemory、Prompts、Guardrails、Observabilityなどのコア機能が動きます。デプロイ方法もAmazon Q Agents、Bedrock Agents、OSSフレームワークと選択肢が増えていて、Day1・Day2で学んだことがここでも繋がってきます。
AWSのベクトルソリューション全体像
AWSにはベクトルストレージの選択肢が複数あり、ユースケースに応じて使い分けます:
| サービス | 特徴 | ユースケース |
|---|---|---|
| Amazon OpenSearch Service | High-performance、Ultra-low latency | リアルタイム検索、低レイテンシが必要な場合 |
| Amazon S3 Vectors | Highly scalable、Cost-efficient | 大規模データ、コスト重視の場合 |
これらはAmazon Bedrock Knowledge Basesと統合されており、RAGアプリケーションのバックエンドとして利用できます。(これは特に新しい情報ではないですが、使い分けとしてのイメージを共有してくれました)
Amazon S3 Vectorsとは
これらの前置きがあった後、具体的にS3 Vectorsの説明になりました。

S3 Vectorsは「ベクトルの保存とクエリをネイティブサポートする、最初のクラウドオブジェクトストア」として位置づけられています。主な特徴は以下の通りです:
- Sub-second: スケール時でも1秒未満のベクトルクエリパフォーマンス
- up to 90%: ベクトルのアップロード、保存、クエリにかかるコストを最大90%削減
- Billions: 数十億のベクトルを低コストで保存
GAでは最大20億ベクトル/インデックスをサポート(プレビュー時の40倍!)。14のAWSリージョンで利用可能になりました。
S3 Vectorsのアーキテクチャ

S3 Vectorsには3つの主要な概念があります:
| コンポーネント | 説明 |
|---|---|
| Vector buckets | ベクトルの保存・クエリに特化した新しいリソースコンテナ |
| Vector indexes | 効率的な類似検索のためにベクトルデータを整理するデータ構造 |
| Vector APIs | PutVectors、GetVectors、DeleteVectors、QueryVectors、ListVectors |
従来のS3がバケットとオブジェクトで構成されていたのに対し、S3 Vectorsではバケットの中にベクトルインデックスがあり、それぞれのインデックスに実際のベクトルが含まれる構造になっています。
OpenSearchとの統合パターン
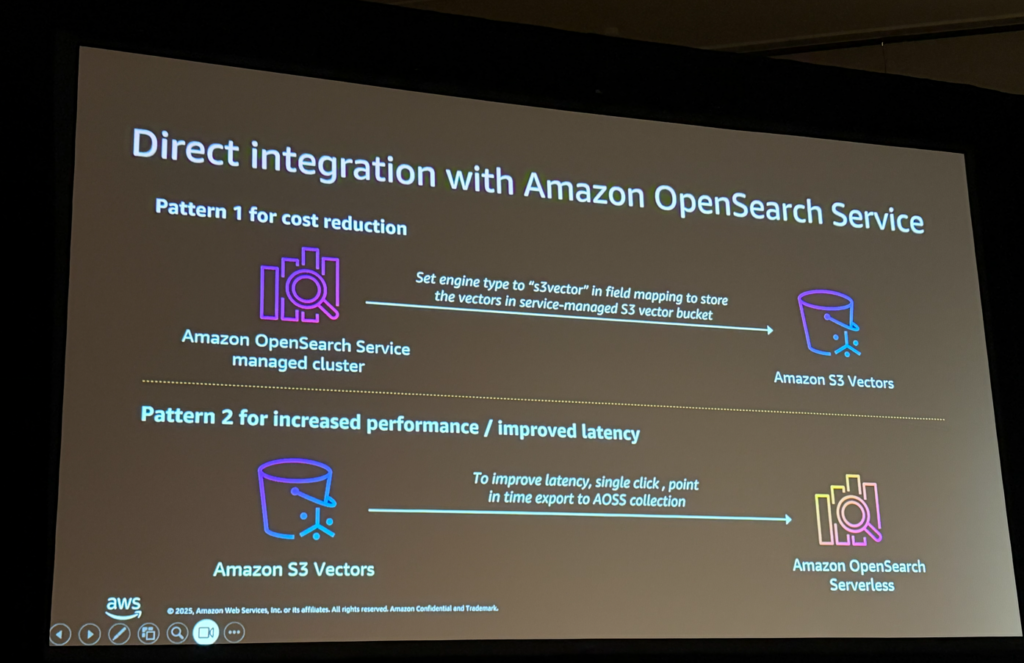
S3 VectorsとOpenSearchの統合には2つのパターンがあります:
Pattern 1: コスト削減向け
- OpenSearch Serviceのマネージドクラスターで、フィールドマッピングのエンジンタイプを「s3vector」に設定
- ベクトルをS3 Vectorバケットに保存し、ストレージコストを削減
Pattern 2: パフォーマンス向上向け
- S3 Vectorsにデータを保存しつつ、レイテンシ改善が必要な場合
- ワンクリックでOpenSearch Serverlessコレクションにエクスポート
用途に応じて使い分けることで、コストとパフォーマンスのバランスを取ることができます。
検索の新しいトレンド

セッションでは、検索の進化についても触れられました:
- Semantic/Hybrid: 語彙検索とセマンティック検索を組み合わせて関連性を向上
- Multi-modal: テキスト、画像、音声など様々なメディアのエンベディングを活用
- Conversational: チャットインターフェースでの検索が一般的に
エージェントのメモリアーキテクチャ
メモリには基本的に2つのタイプがあります:
- 短期メモリ: セッション中の会話履歴など(Elastic Cacheなどを使用)
- 長期メモリ: 過去のインタラクションや学習した内容を保持
「チャットボットとのセッションが終わると忘れてしまう」という従来の課題に対して、長期メモリを導入することで、ユーザーの好みや過去のインタラクションを記憶できるようになります。
S3 Vectorsはこの長期メモリのストレージとして最適で、セマンティック検索を使って「この件について記憶があるか?」といったクエリを高速に処理できます。
ここはAgentCore Memoryとの使い分けが必要だと思います。まずはAgentCore Memoryを使ってみようと思います。
トラストでの活用可能性
S3 Vectorsは以下のようなユースケースで活用できそうです:
- RAGシステムのベクトルストレージ: Bedrock Knowledge Basesと統合してコスト削減。これまでのOpen Search Serverless、Pineconeから進化する必要がありますね。
- エージェントの長期メモリ: ユーザーごとの好みや履歴を記憶、今日のkeynoteではエピソード記憶といった機能も出てきました。こちらも今後検証していきます。
- 階層型検索戦略: S3 Vectorsで大規模データを保存し、高頻度クエリはOpenSearchにエクスポート
特に「大量のベクトルデータをコスト効率よく保存し、必要に応じてOpenSearchと連携」というハイブリッドパターンは、実際のプロダクション環境で非常に有用だと感じました。
最後にはスピーカーの方からステッカーをいただきました!Expo以外のセッションでGetしたのは初めてです。

参加セッション 2: AIM3324 | Amazon Nova 2 Omni: A new frontier in multimodal AI

2つめのセッションは、昨日のKeynoteで発表されたAmazon Nova 2 Omniについての詳細解説です。
このセッションに参加した目的は、画像や動画の認識精度を確認するためです。
トラストではYOLOを使って画像内の特定物体を検知しバウンディングボックスで囲んだり、Amazon Rekognitionを使ったりしていますが、これまでの生成AIモデルでは特定の物体に対する座標の認識が全くできていなかったため、生成AIによる物体の位置特定はしていませんでした。
Nova 2 Omniでどこまでできるようになったのか、非常に気になっていました。
Amazon Nova 2ファミリー

まず、Nova 2ファミリー全体の紹介がありました:
| モデル | 提供状況 | 特徴 |
|---|---|---|
| Nova 2 Lite | GA | 高速・低コストの推論モデル、日常的なワークロード向け |
| Nova 2 Pro | Preview | 最も知的な推論モデル、高度に複雑なタスク向け |
| Nova 2 Omni | Preview | マルチモーダル理解+画像生成を統合したモデル |
| Nova 2 Sonic | GA | 音声対音声モデル、リアルタイムの人間らしい会話型AI |

各モデルの詳細スペックは以下の通りです:
| 項目 | Nova 2 Lite | Nova 2 Pro | Nova 2 Omni | Nova 2 Sonic |
|---|---|---|---|---|
| Context window | 1M | 1M | 1M | 1M |
| Languages | 200+ | 200+ / 10 speech | 200+ / 10 speech | 7 languages / 22 voices |
| Input | Text, Image, Video | Text, Image, Video, Audio | Text, Image, Video, Audio | Speech, Text |
| Output | Text | Text | Text, Image | Speech, Text |
注目すべきは、Nova 2 Omniだけが画像を出力できる点です。理解と生成を1つのモデルで実現しています。
Nova 2 Omniの特徴

Nova 2 Omniは「すべてのモダリティを理解し、テキストと画像を生成する1つのモデル」として位置づけられています。
主なメリット:
- 人間のように情報をネイティブに解釈: 複数の入力を自然に理解
- コンテキストを保持して、より正確で一貫性のある結果を生成: 単一モデルだからこそ可能
- オールインワンモデル = エンジニアリング削減、コスト削減、価値創出までの時間短縮

Nova 2 Omniの5つの強み:
| 機能 | 説明 |
|---|---|
| Hybrid reasoning model | ハイブリッド推論モデル |
| State-of-the-art in multimodal perception | 同価格帯で最先端のマルチモーダル認識 |
| Cross-modal reasoning | クロスモーダル推論 |
| Audio Understanding | 音声理解 |
| Image Generation and Editing | 画像生成・編集 |
ユースケース 1: Document Understanding(ドキュメント理解)

主な機能:
- Intelligent Document Processing with high accuracy (reasoning): 推論を伴う高精度なドキュメント処理
- Optical Character Recognition (OCR): 光学文字認識
- Key Information Extraction (KIE): 重要情報の抽出

OCRのデモでは、複雑なレイアウトの地図画像(COVID-19の地域別感染者数)から、すべての数値とラベルを正確に抽出していました。
特徴:
- Robust real-world OCR(堅牢な実世界OCR)
- Mixed-content understanding(混合コンテンツの理解)
- Structured outputs(構造化出力)

Key Information Extractionでは、複雑なレイアウトの契約書から、スケジュールや金額などの重要情報を抽出していました。
特徴:
- Schema-driven extraction(スキーマ駆動の抽出)
- Layout-aware text extraction(レイアウトを考慮したテキスト抽出)
- Reasoning-based validation(推論ベースの検証)
ユースケース 2: Audio Understanding(音声理解)

主な実績:
- MMAU(音声理解と推論のベンチマーク)で第2位
- Speech transcription, summarization, Q&A with tool calling
- Multi-speaker diarization(複数話者の分離)
- 10言語に対応
ユースケース 3: Image and Video Understanding(画像・動画理解)

これが今回最も注目していた機能です。3つの観点で説明がありました:
1. Perception & Object Detection(知覚と物体検出)
- フレームごとに物体領域を正確に検出し、バウンディングボックスを適用
- ロゴ検出
- Dense captioning(詳細なキャプション生成)
2. Visual-QA and Reasoning(視覚的Q&Aと推論)
- Dense captioning
- 正確なVision Question-Answering
- 微妙なアクションの解釈
3. Temporal Understanding(時間的理解)
- キーイベントのタイムスタンプ抽出
- 因果関係の理解
- シーン理解の向上

デモでは、リビングルームの画像に対して「この画像の中にある植物を特定して」と指示したところ、植物、ソファ、テーブル、テレビなどを正確に検出し、バウンディングボックスを生成していました。
正直な感想として、植物の特定と座標の特定ができていたのは驚きました! これまでの生成AIモデルではここまでの精度は出ていなかったので。ただ、デモを見ると植物以外の物体(ソファやテーブル)にもバウンディングボックスが付いており、特定の物体だけを検出するには追加の工夫が必要そうです。Nova 2 Omniは現在Previewなので、GA後のさらなる精度向上に期待したいですね!
ユースケース 4: Image Generation(画像生成)

主な特徴:
- High-quality realistic images such as people(人物など高品質でリアルな画像)
- Text rendering(テキストレンダリング)
- Spatial understanding for image layout(画像レイアウトの空間理解)
ユースケース 5: Image Editing(画像編集)

Nova 2 Omniは9種類の編集操作をテキストプロンプトだけでサポートしています:
| 操作 | 説明 |
|---|---|
| Add | 画像に新しいオブジェクトを追加 |
| Alter | オブジェクトの属性を変更 |
| Extract | 指定したオブジェクトを抽出 |
| Replace | オブジェクトを別のものに置換 |
| Remove | オブジェクトや領域を削除 |
| Background change | 背景を変更 |
| Style transfer | 全体のスタイル、トーン、外観を変更 |
| Motion change | シーン内のオブジェクトの動きを変更 |
| Hybrid edit | 複数の操作を1つの指示で組み合わせ |
理解モデルと生成モデルが一体化しているため、「この帽子を削除して、ドレスの色を赤に変えて」といった複合的な編集も1回のプロンプトで実行できます。
トラストでの活用可能性
Nova 2 Omniは以下のようなユースケースで活用できそうです:
- 物体検出の補助: YOLOやRekognitionと組み合わせて、より高度な物体認識
- ドキュメント処理: 複雑なレイアウトのPDFや契約書から情報を抽出
- 画像編集の自動化: マーケティング素材の大量生成・編集
- 動画分析: 長時間の映像から重要なシーンやイベントを自動抽出
特に物体検出とバウンディングボックス生成については、GA後に本格的な検証を行いたいと思います。従来のYOLO + Rekognitionのパイプラインを、Nova 2 Omniで置き換えられる可能性があるかもしれません。またOCRについて、これまで別のモデルを使ってプロンプトの工夫などが必要でしたが、この辺りの大変さを緩和しれくれる可能性を感じました。GAを楽しみにしています。
参加セッション 3: SAS302 | SaaS Anywhere meets GenAI: Building distributed AI multi-tenant environments
3つめはハンズオンセッションです。「SaaS Anywhere」という比較的新しい概念と、生成AIを組み合わせたマルチテナント環境の構築を学びました。
SaaS Anywhereとは


「SaaS Anywhere」という用語を知っている人はいますか?という質問に、会場ではほとんど手が上がりませんでした。(私も知らなかったです)
通常のSaaS環境では、コントロールプレーン(ユーザー管理、テナント管理、課金など)とアプリケーションプレーン(機能サービスとデータ)の両方がSaaSプロバイダーのアカウントに存在します。
しかし、エンタープライズのお客様からは以下のような要件が出てくることがあります:

- コンプライアンス要件: データを自社環境から出せない
- コスト効率: 大量のデータを自社で管理した方が安い
- レガシーシステム連携: 既存システムとの統合が必要
- レイテンシー要件: データの近くで処理したい
これらの要件に対応するため、SaaSアプリケーションの一部を顧客のアカウントに配置するアーキテクチャパターンがSaaS Anywhereです。
4つのデプロイメントモデル
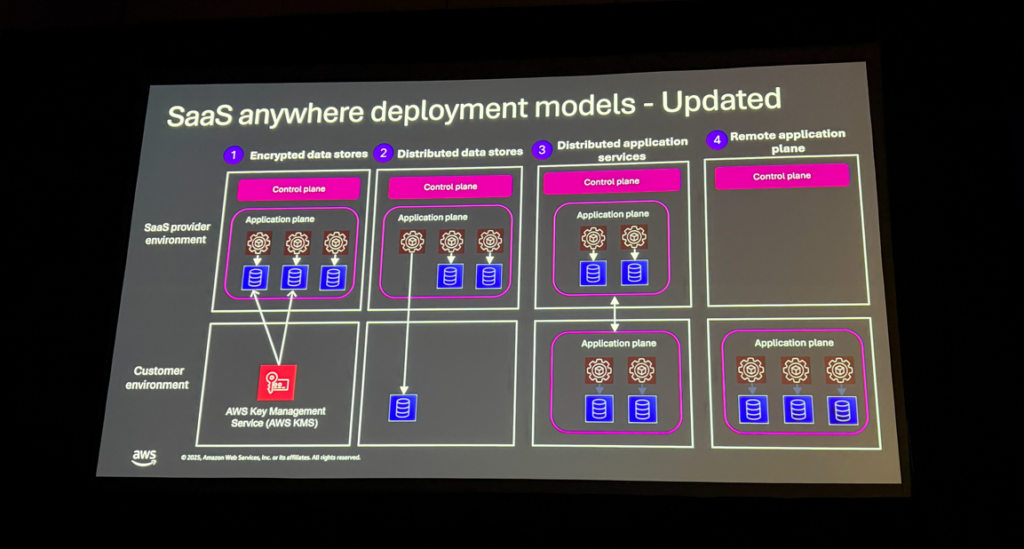
| モデル | 内容 | 侵入度 |
|---|---|---|
| Model 1 | データは顧客管理のKMSキーで暗号化 | 最小 |
| Model 2 | 特定のデータセットを顧客環境に保持 | 中 |
| Model 3 | データと関連コンピュートを顧客アカウントに移動 | 大 |
| Model 4 | 全リモートアプリを顧客アカウントに配置(コントロールプレーンのみプロバイダー側) | 最大 |
「可能であれば、これらのモデルを採用しない方が良い」とのこと。管理がどうしても大変になるからですね。しかし、顧客の要件によっては採用が必要になります。アジリティ(パッチ適用や新機能追加の容易さ)とのトレードオフになります。
ハンズオンの内容
ハンズオンでは、実際にプロバイダーアカウントとカスタマーアカウントの2つのAWSアカウントを使って、以下の3つのLabを実施しました。

Lab 1: Customer-Managed Encryption Keys
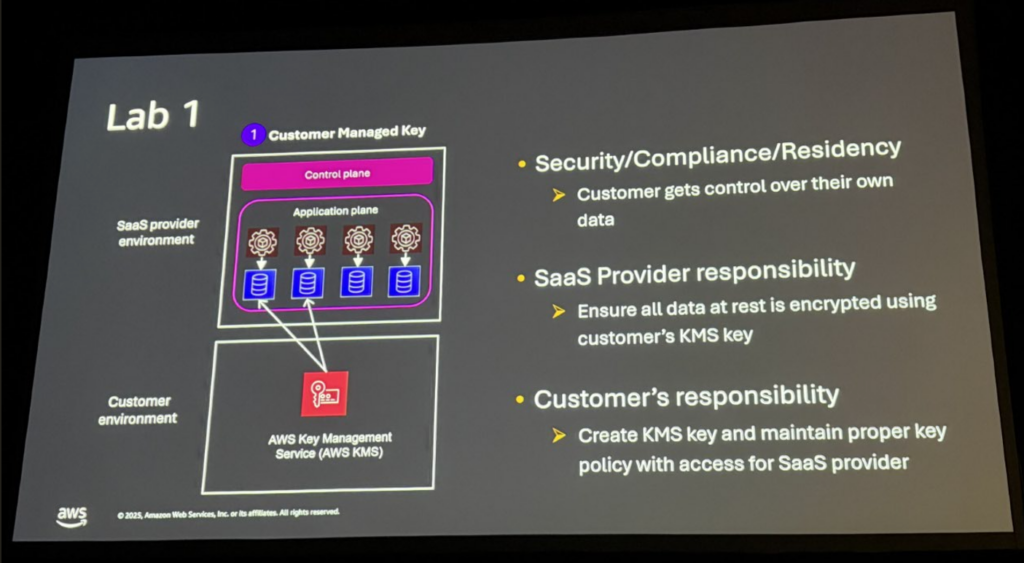
顧客が管理するKMSキーでデータを暗号化するパターンです。
- S3バケット、Aurora Serverless、Secrets Managerを顧客のKMSキーで暗号化
- 顧客はキーポリシーの変更で即座にアクセスを取り消し可能
これは「データはプロバイダー側にあるが、暗号化キーは顧客が管理」というModel 1のパターンです。顧客がキーを無効化すれば、プロバイダーはデータにアクセスできなくなります。
Lab 2: Distributed Data Store Model
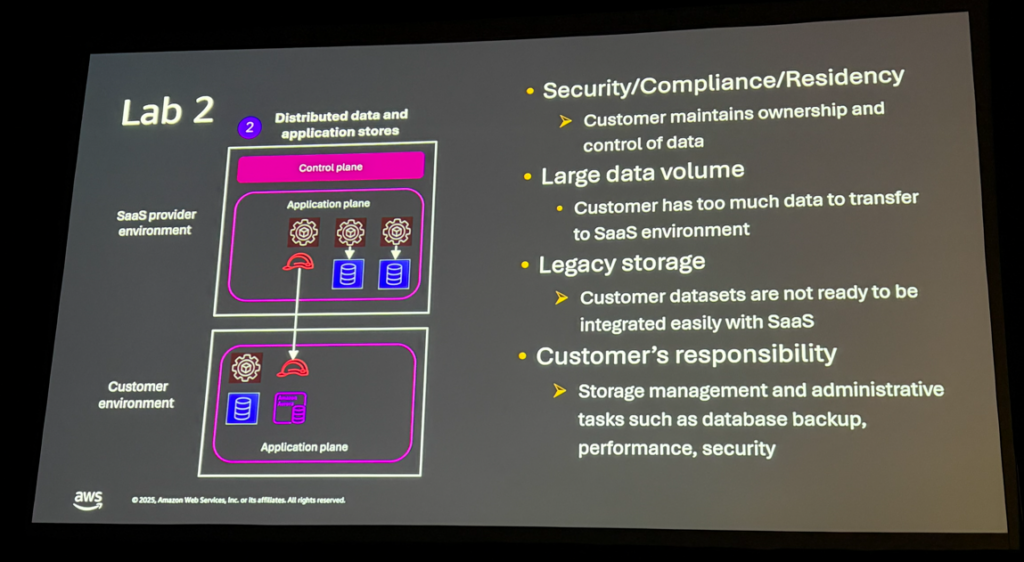
Knowledge Base、ベクトルDB、S3を顧客アカウントに配置するパターンです。
このLabでは、テナントごとに異なるKnowledge Baseを使い分ける仕組みを実装しました:
- テナントIDからDynamoDBでKnowledge Base IDを取得
- STSでクロスアカウントのロールをAssume
- 顧客アカウントのBedrock Knowledge Baseにアクセス
# テナント設定に基づいてBedrock Clientを作成
def createBedrockClient(config):
if config["tenantSpecificKB"]:
# STSでリモートアカウントのロールをAssume
response = sts_client.assume_role(
RoleArn=config["roleArn"],
RoleSessionName='MyAssumedRoleSession',
ExternalId=config["externalId"]
)
# 一時クレデンシャルでクライアント作成
...
Day1・Day2で学んだABACとメタデータフィルターによるテナント分離に加えて、クロスアカウントでのデータ分離という選択肢があることを学びました。
Lab 3: Cross-Account Observability
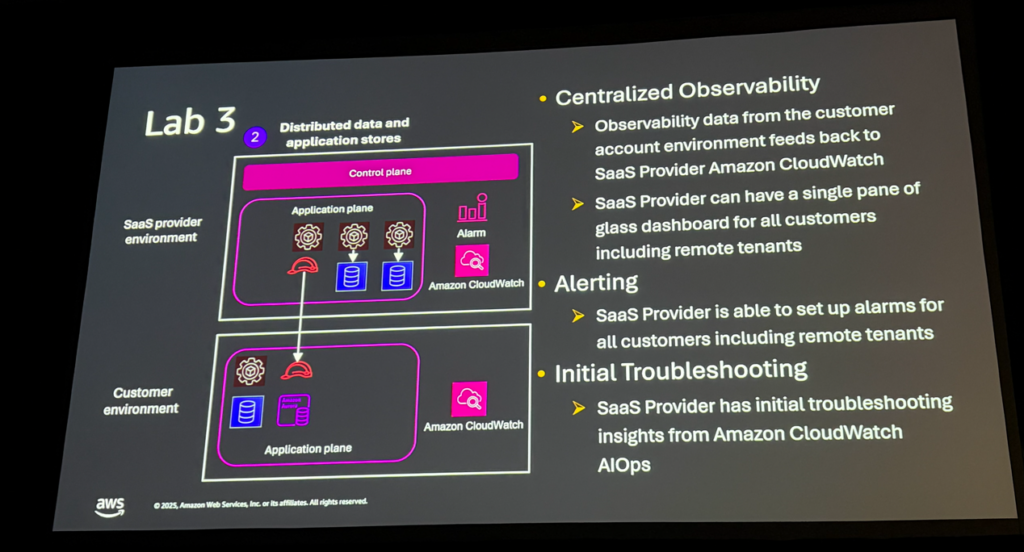
CloudWatch Cross-Account Observabilityを使って、分散環境を一元監視するパターンです。
これは実際のユースケースから生まれたLabとのこと。CSM(カスタマーサポートマネージャー)やTAM(テクニカルアカウントマネージャー)がISV(独立系ソフトウェアベンダー)のトラブルシューティングをしようとした際、リモートの顧客アカウントにアクセスできず困っていたそうです。
CloudWatchのクロスアカウント機能を使えば、顧客アカウントのログやメトリクスをSaaSプロバイダー側で一元的に確認できます。アラームも設定可能です。
トラストでの活用可能性
SaaS Anywhereのパターンは、以下のようなケースで活用できそうです:
- 金融・医療などコンプライアンス要件が厳しい業界向けSaaS: 顧客データを顧客環境に保持
- エンタープライズ向けオプション: 標準はModel 1、プレミアムはModel 2〜4を提供
- ハイブリッドクラウド対応: オンプレミスとの連携が必要なケース
Day1・Day2で学んだマルチテナントパターンに加えて、マルチアカウントという軸が加わりました。実際のエンタープライズ向けSaaS開発では重要な選択肢になりそうです。
まとめ
以上、「AWS re:Invent 2025 現地レポート Day3」でした!
Day3は3つのセッションを通じて、以下のことを学びました:
- S3 Vectors: エージェントの長期メモリに最適。コスト効率とスケーラビリティに優れる
- Nova 2 Omni: マルチモーダル理解+生成を1つのモデルで。複雑なパイプラインが不要になるか?
- SaaS Anywhere: 顧客アカウントにデータやコンピューティングリソースを配置する4つのパターン
3日間を通じて「エージェント × マルチテナント × スケーラビリティ」というテーマが一貫していました。
- Day1: Agent Coreによるマルチテナントエージェントの基礎
- Day2: 実際のハンズオンでABACやメタデータフィルターを体験
- Day3: S3 VectorsやSaaS Anywhereでさらにスケールする方法
これらの技術を組み合わせることで、エンタープライズグレードのAIエージェントシステムを構築する道筋がかなり明確に見えてきました。試したいことがたくさんありすぎます!
早く帰国して没頭して開発がしたいです笑
明日のDay4はいよいよre:Invent参加最終日!
Strands Agents SDK for TypeScript、マルチテナントアカウントのテストパターンなど、これまでの3日間にさらに知識の積み上げをしていきます!
また投稿しますので、お楽しみに!


