AWS re:Invent 2025 現地レポート Day4

はじめに
本記事ではAWS re:Invent 2025のDay4の現地の様子について、参加したセッションの内容や最新情報をご紹介します。本日はついにre:Invent最終日です!
1日のスケジュール
12/4(木)のDay4では、3つのセッションに参加しました。今日はエージェント開発からSaaSレジリエンス、Agentのオブザーバビリティについて学んできました!
| 時間 | 内容 |
|---|---|
| 11:00 AM – 12:00 PM | AIM3331: Build production AI agents with the Strands Agents SDK for TypeScript |
| 1:00 PM – 2:00 PM | ISV404-R1: Build resilient SaaS: multi-account resilience testing patterns |
| 2:30 PM – 3:30 PM | AIM3329: Build trust in production agents with AgentCore Observability ft Sony |
参加セッション 1: AIM3331 | Build production AI agents with the Strands Agents SDK for TypeScript


1つめのセッションは、AWSが開発したオープンソースのエージェントフレームワーク「Strands Agents SDK」についてです。今週TypeScript版がリリース(preview版)されたということで、開発チームから直接話を聞きたくて参加しました。
登壇者はAmazonのPrincipal Product ManagerのRyanさんと、TypeScript SDKのテクニカルリードを務めたSenior Software EngineerのNickさんです。Ryanさんは「たくさんの人と話しすぎて昨日声が枯れてしまった」と言っていました笑
Strands Agents SDKとは

Strands Agents SDKは、わずか数行のコードでAIエージェントを構築できるフレームワークです。5月にPython版がリリースされ、今回のre:InventでTypeScript版がプレビューリリースされました。
import { Agent } from '@strands/agents';
import { tools } from '@strands/tools';
const agent = new Agent({
tools: tools,
});
await agent.run("What's the weather in Las Vegas?");
これだけでエージェントループが動くというのは驚きですよね。Bedrockをデフォルトのモデルプロバイダーとして、ツールを使いながらゴールを達成するエージェントが動作します。
Python版は5月のリリース以来、500万回以上ダウンロードされているとのこと。Day2のKeynoteでも紹介されていましたね。
Model-Driven Agent という考え方
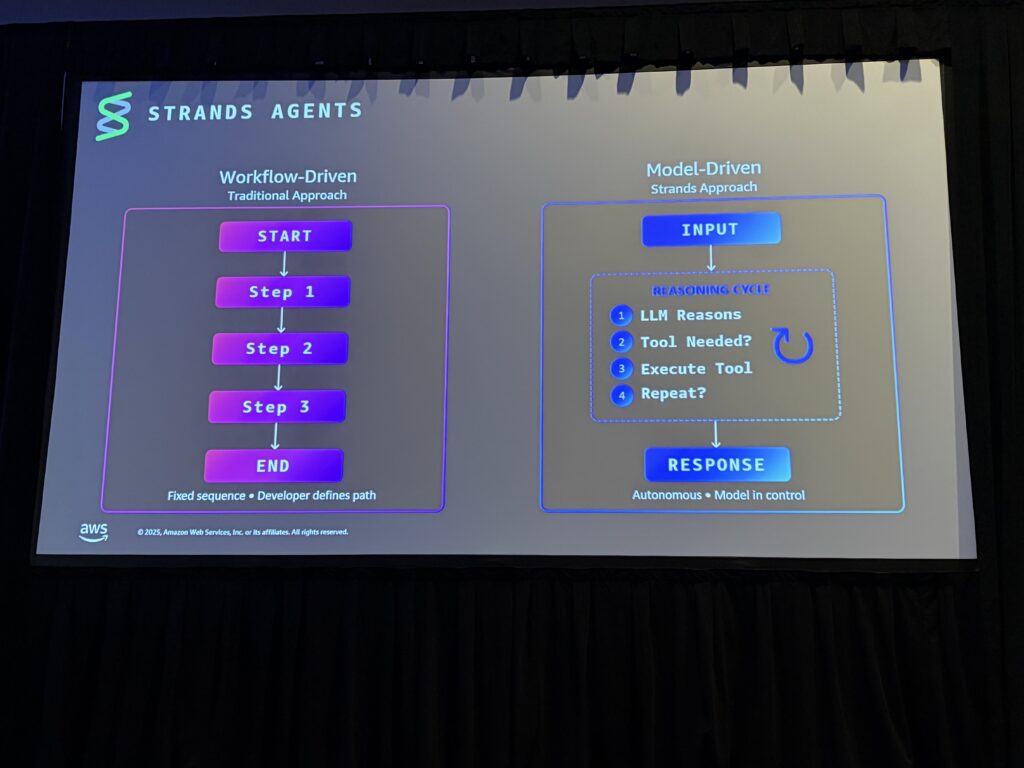
セッションで特に強調されていたのが、「Model-Driven Agent」 というアプローチです。
従来のエージェント開発では「Workflow-Driven」なアプローチが主流でした。開発者がワークフローのステップを事前に定義し、「まずネットワーク接続を確認」「次にセキュリティグループをチェック」といった具合に細かく制御します。
Ryanさんは、「これだとプロトタイプに数ヶ月かかることもある。新しいシナリオに対応するたびにワークフローの追加が必要だし、壊れたときのデバッグも大変」と言っていたのが印象的でした。確かに、LLMの呼び出しをひとつひとつ制御するのは骨が折れますよね。Step FunctionsのState Machieneと結局大差がなくなってしまうな、と以前から思っていました。
一方、Model-Drivenなアプローチでは:
- ゴール(システムプロンプト)を与える
- ツールを装備させる
- あとはモデルに任せる
モデル自身がタスクを分解し、どのツールをどの順番で使うか判断し、結果を評価して次のアクションを決定します。開発者は「制御」ではなく「ステアリング(誘導)」に集中すればいい、という考え方です。

Strandsの設計原則

AWSらしく、StrandsにもTenets(設計原則)定められています:
| 原則 | 内容 |
|---|---|
| Simple at any scale | プロトタイプから本番環境まで同じシンプルな抽象化 |
| Extensible by design | モデルプロバイダー、ツール、フックなど全てが拡張可能 |
| Composability | プリミティブが一貫したビルディングブロックとして連携 |
| The obvious path is the happy path | 直感的なAPIがベストプラクティスへ導く |
| Accessible to humans and agents | 人間とエージェント両方にアクセス可能 |
| Embrace common standards | 既に広く採用されているものを再発明しない |
実際に、Strands AgentsにはMCPサーバーが用意されており、CursorなどのAIコーディングアシスタントがStrandsのドキュメントを検索・取得できるようになっています。
人間だけでなく、AIエージェントにもアクセスしやすい設計を意識しているというわけです。
Agent SOPs – エージェントへの指示の標準化

後半で紹介されたAgent SOPs(Standard Operating Procedures)が非常に興味深かったです。
これは、エージェントに対して自然言語で構造化された手順を与えるフォーマット。RFC 2119のキーワード(MUST、SHOULD、MAY等)を使って、エージェントの行動を制御します。
## Steps
### Step 1: 要件の確認
- MUST: 実装する機能の要件を確認する
- SHOULD: 不明点があれば質問する
### Step 2: テストの作成
- MUST: 実装前にテストを書く
- MUST NOT: テストなしでコードを書かない
「Amazon内部で5,000以上のSOPsが作られて使われている。エージェントの振る舞いが予測可能になり、デバッグも容易になった」
これは社内のAI駆動開発でも参考になりそうですね。プロンプトエンジニアリングの一種ですが、フォーマットが決まっているのでチームで共有しやすいです。
TypeScript SDKの開発秘話 – StrandsでStrandsを作る
後半はNickさんにバトンタッチ。(写真が無かった。。)
TypeScript SDKの開発プロセスについて、面白い話がありました。
なんと、Strands Agents SDK(Python版)を使ってTypeScript版を開発したというのです!単なるバイブコーディング(AIにおまかせ)ではなく、かなり工夫されていました。
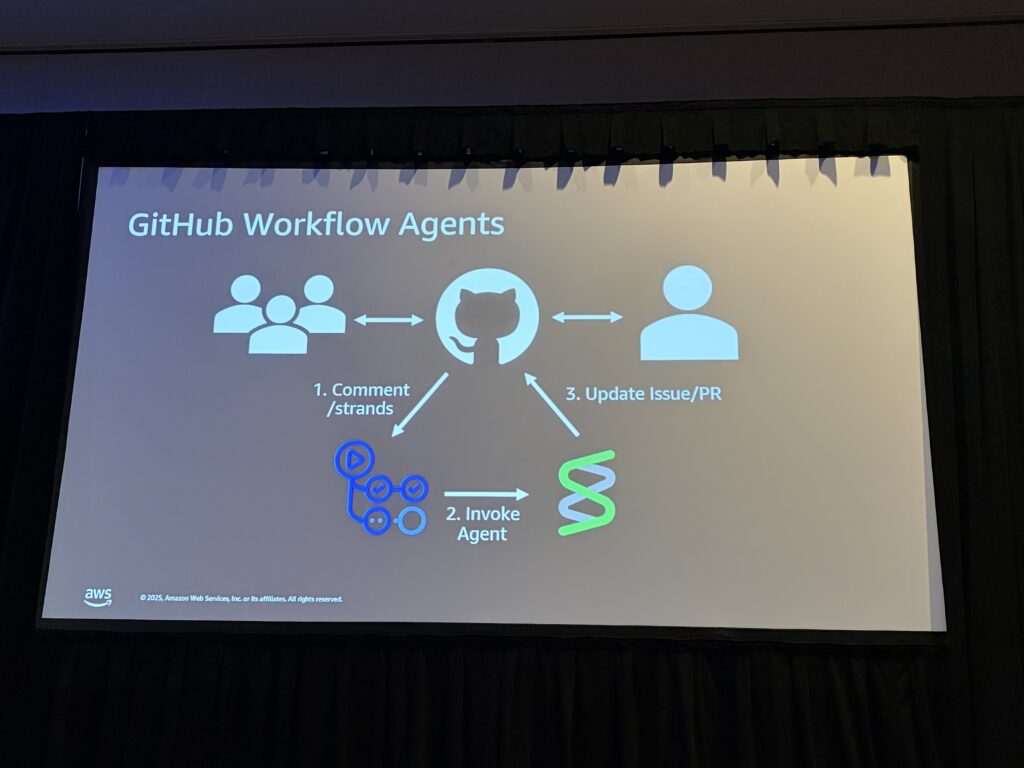

具体的には、GitHub Actionsと連携した2つのエージェントを活用:
1. Refiner Agent(要件を明確化)
- GitHubのIssueを読み込み、コードベースを探索
- 実装に必要な質問をコメントとして投稿
- 開発者との対話を通じて要件を明確化
2. Implementer Agent(実装)
- 明確化されたタスクを受け取り、ブランチを作成
- テスト駆動開発(TDD) で実装
- Pull Requestを作成し、フィードバックを反映

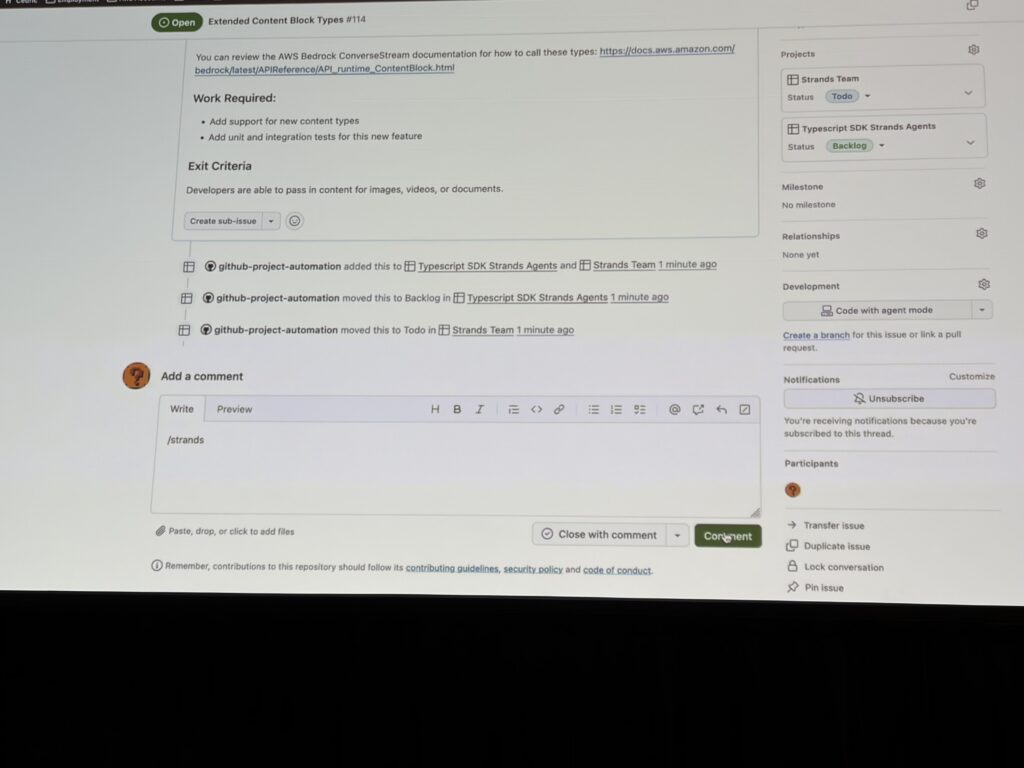
デモ動画では、IssueにコメントでSlash command(/strands)を打つと、エージェントがIssueを読んで質問を返し、それに回答するとさらに深掘りして…という流れが紹介されていました。最終的にエージェントが「実装可能な状態になった」と判断すると、実装フェーズに移行します。
この開発手法は一度検証してみたいと思います。
エージェントがチーム最大のコントリビューター
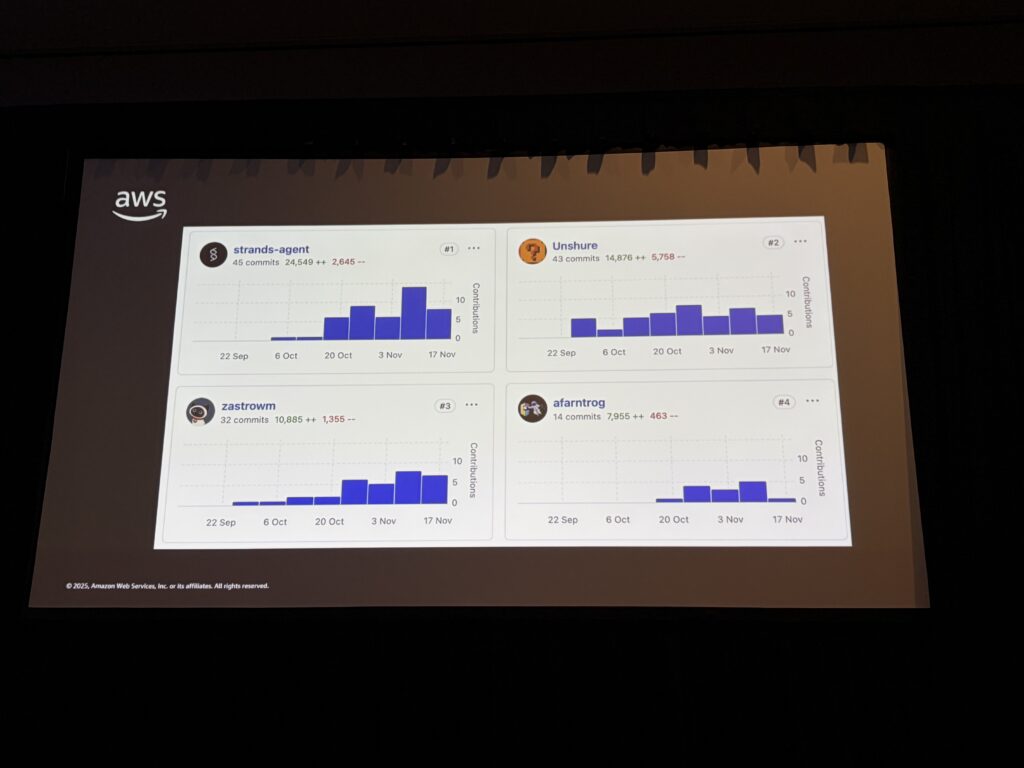
衝撃だったのがこのスライド。TypeScript SDKのリポジトリで、最もコードをコントリビュートしているのがこのエージェントでした。
Nickさん本人が43コミット・約14,000行なのに対し、エージェントはそれを上回る貢献をしています。
「チームのプリンシパルエンジニアは『通常半日かかる作業が、3回の20分セッション(計1時間)で終わった』と言っていた。4倍の効率化」
もちろん全部がうまくいくわけではなく、複雑なタスクは人間が担当しているとのこと。でも、低〜中程度の複雑さのタスクをエージェントに任せることで、エンジニアは高複雑度のタスクに集中できるようになったそうです。完全な”バイブコーディング”ではなく、補助ツールとして使っているとのことで、非常に勉強になりました。
その他の新機能
セッションでは他にも以下の機能が紹介されました:
- Steering機能(実験的): ライフサイクルフックでエージェントの軌跡を評価し、フィードバックを注入。プロンプトを小さく保ちつつ制御できる
- Evaluationsライブラリ: エージェントの評価を簡単に実装。合成データセット生成機能付き
トラストでの活用可能性
このセッションを通じて、以下の点でトラストでの活用を検討したいと思いました:
1. TypeScript版でフロントエンドアプリへの組み込み
React/Next.jsアプリケーションに直接エージェント機能を組み込めるようになります。これまでPythonバックエンドを経由していた部分を、フロントエンドで完結させることも検討できそうです。
2. Agent SOPsの手法を社内AI開発に応用
プロンプトエンジニアリングの標準化として、SOPsのフォーマットは参考になります。チームで共有しやすく、デバッグもしやすい。
3. GitHub連携のエージェント開発フロー
社内の開発プロセスにも導入を検討したいですね。特にコードレビューの効率化や、定型的な実装タスクの自動化に期待です。
4. Model-Drivenアプローチの検討
Day1・Day2で学んだAgent Coreと組み合わせて、Strandsでエージェントを実装するパターンは有力な選択肢になりそうです。
TypeScript版はまだプレビューなので実験程度で触ってみますが、まずはPython簡単なプロトタイプを作ってみたいと思います。この辺りも帰国後に記事にしようと思います。
参加セッション 2: ISV404-R1 | Build resilient SaaS: multi-account resilience testing patterns
{写真: セッション会場の様子}
2つめのセッションは、SaaSアーキテクチャにおけるレジリエンステストパターンについてです。AWS Fault Injection Service(FIS)を使って、マルチテナント環境でどのように障害注入テストを行うかというテーマで、実際のデモを交えた非常に実践的な内容でした。
「深夜3時にマルチテナントSaaS環境の障害で複数顧客に影響が出た、あのパニックになる電話を経験したことがある人はいますか?」
冒頭でこう問いかけられ、会場から多くの手が上がっていました。そんな状況を事前に検証して防ぐためのベストプラクティスを学べるセッションです。Level400のセッション、かつあまり知識のない領域だったので、ついていくのに精一杯でした。。
SaaSの6つの基本原則

成功するマルチテナントSaaSソリューションには、以下の6つの重要な柱が必要だと説明がありました:
| 柱 | 内容 |
|---|---|
| テナント分離 | セキュリティ・データ漏洩を防止 |
| ノイジーネイバー対策 | 特定テナントの負荷が他テナントに影響しないよう制御 |
| ID・認可管理 | テナントが境界を超えてアクセスできないよう管理 |
| 課金・計測 | テナントの使用量を正確に把握し課金 |
| 信頼性テスト | 障害に対する耐性を検証 |
| オブザーバビリティ | システムの状態を可視化 |
「これらの原則をAWS Well-Architected Framework の信頼性の柱と組み合わせて、レジリエントなSaaSを構築することが重要」
ここまでは知っている知識でした。
AWS Resilience Lifecycle Framework
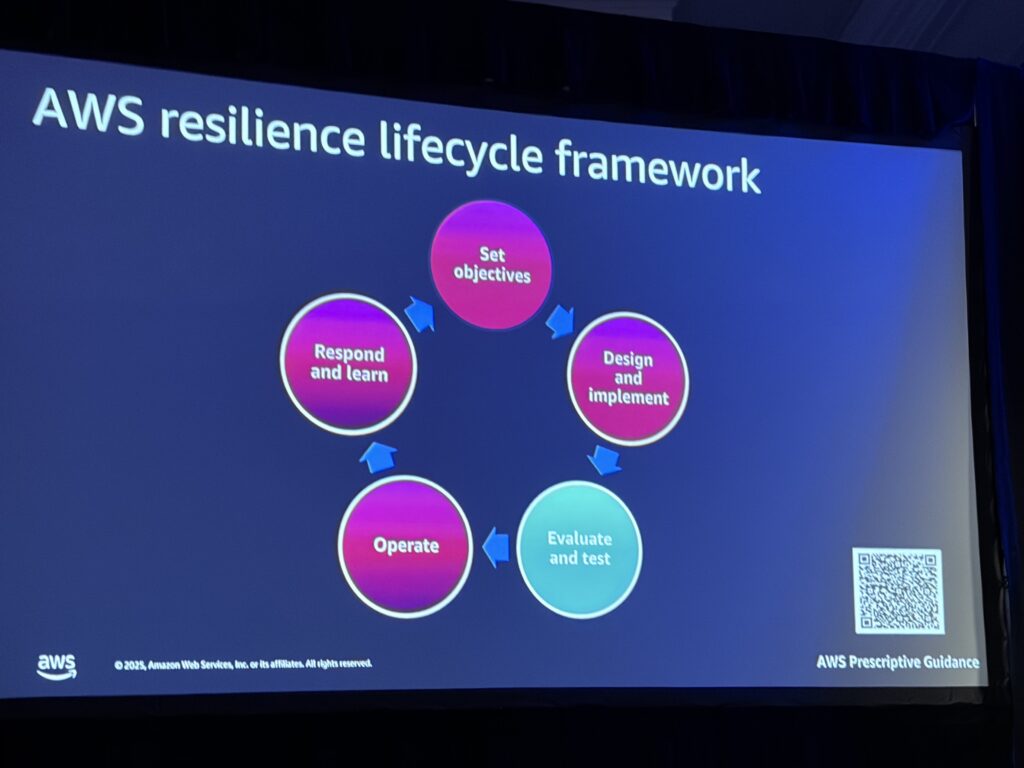

AWSが提唱するResilience Lifecycle Frameworkは、以下の5つのステージで構成されています:
- Set Objectives(目標設定)
- どのレベルのレジリエンスが必要か?
- SLA/SLO/SLIの定義
- ビジネス要件から技術要件へ逆算
- Design and Implement(設計・実装)
- 障害モードを予測
- 技術的な設計選択
- Evaluate and Test(評価・テスト)
- ここがFISの出番!
- レジリエンス評価、DR テスト
- 障害注入テスト
- Operate(運用)
- 本番環境へのデプロイ
- モニタリング・アラート設定
- Respond(対応)
- インシデント対応
- ランブック・プレイブック
AWS Fault Injection Service(FIS)とは

AWS Fault Injection Service(FIS)は、制御された障害をワークロードに注入してレジリエンスを検証するサービスです。
主な特徴:
- EKS: Pod CPUストレス、IOストレス、レイテンシー注入
- Lambda: レイテンシー、HTTPエラーレスポンス
- API Gateway: HTTPレイテンシー
- カスタム障害: SSM Documentsで独自の障害を定義可能
「カオスを起こすためではなく、制御された実験を行うためのツール。Stop Conditionを設定して、閾値を超えたら自動停止させることが重要」とのことでした。難しい。。
デモアーキテクチャ: RAGアプリケーション
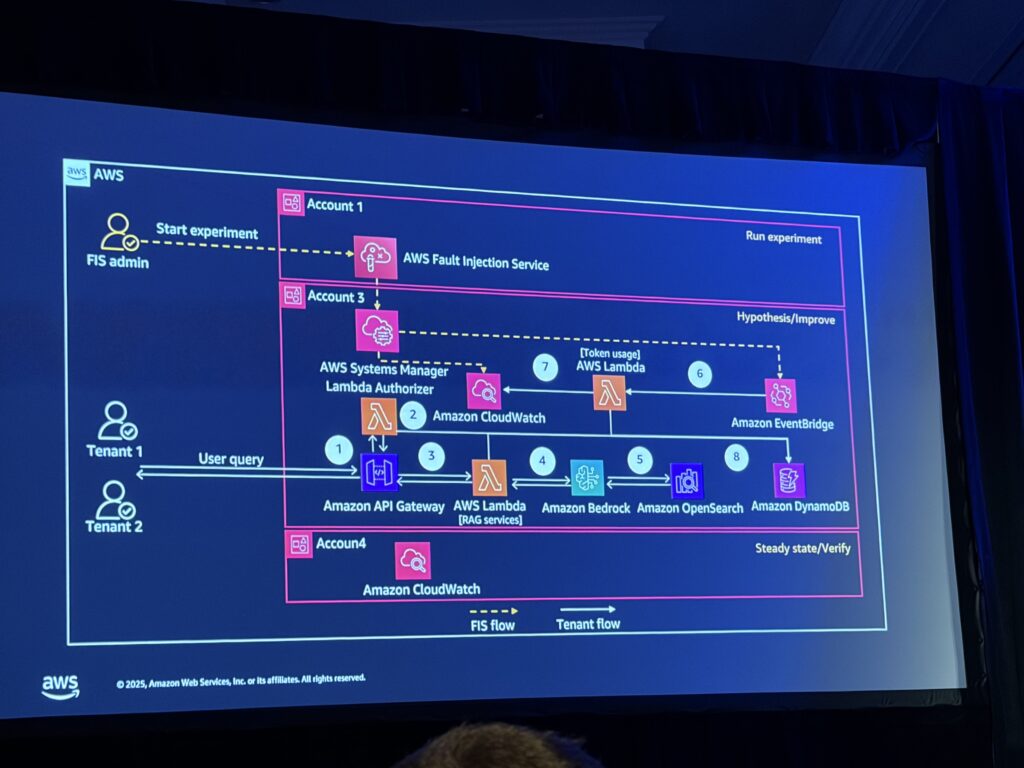
今回のデモでは、SaaS Builder ToolkitをベースにしたRAGアプリケーションが使用されました。
ワークフロー:
1. テナント → API Gateway (Usage Plan: 10,000入力トークン, 500出力トークン, 100リクエスト/日)
2. Lambda Authorizer → JWT検証 + DynamoDBで使用量チェック
3. IAMロール動的生成 (ABAC: Attribute-Based Access Control)
4. Lambda RAGサービス → Bedrock Knowledge Base (OpenSearch VectorStore)
5. Amazon Bedrock LLM → レスポンス生成
2つのテナントが設定されています:
- Tenant 1: セキュリティISV(脅威データを扱う)
- Tenant 2: HR Tech ISV(従業員表彰データを扱う)
パターン1: マルチテナント ノイジーネイバーテスト
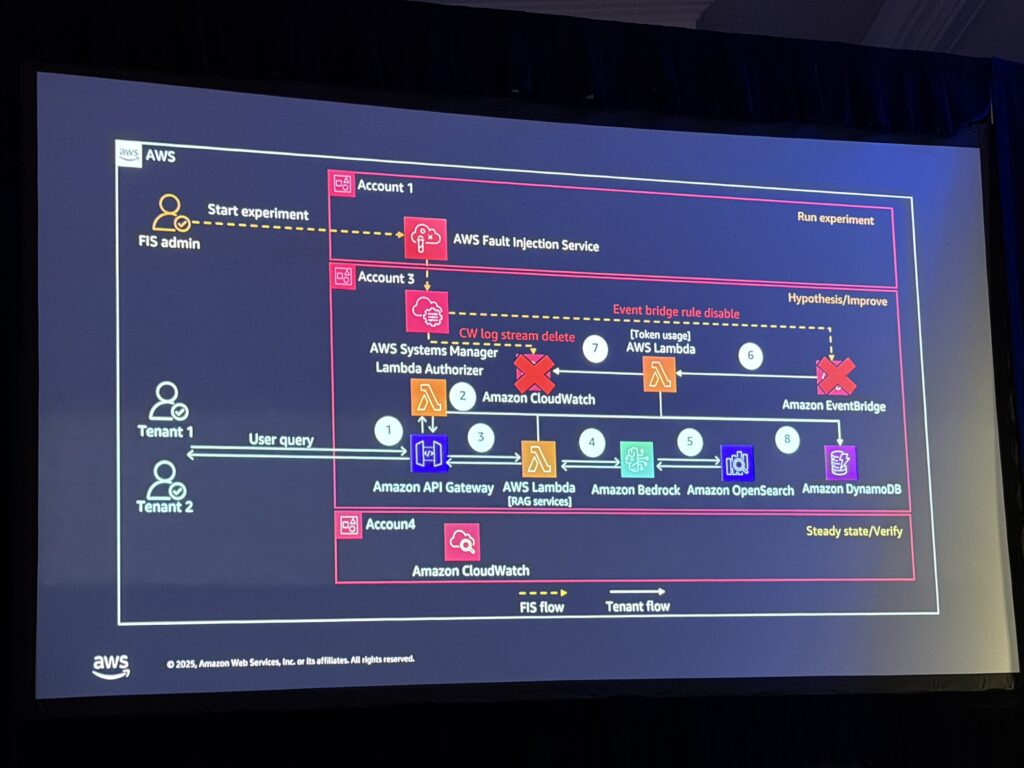
シナリオ: 1つのテナントの活動が全体のサービスパフォーマンスに悪影響を与える状況
テスト内容:
- EventBridgeルールを無効化(使用量モニタリングを停止)
- CloudWatchログストリームを削除(トークン使用量の追跡を停止)
- テナントが使用量制限を超えてリクエストできるか検証
デモの流れ:
登壇者がターミナルから13件のリクエストを送信すると、最初の8件は成功しますが、リクエスト9〜13はHTTP 403(Access Denied)で失敗。これはDynamoDBで事前定義済みのテナントのトークン使用量を追跡し、制限を超えた場合にブロックする仕組みが正常に動作しているためです。
次に、FIS実験を実行して上記の障害を注入。その後、同じリクエストを送信すると…
「本来ブロックされるはずの13件のリクエストが全て成功してしまいました。これが実際の障害時に起こりうるシナリオです」
改善策:
- Service Control Policy(SCP)をアカウント・OU・リージョンレベルで設定
- クォータ制限の事前引き上げ申請
- 複数の防御層を設ける
パターン2: テナント分離テスト

シナリオ: 開発者のミスで、テナント1のコードにテナント2のKnowledge Base IDがハードコードされた場合
テスト内容:
ABACを採用していても、マイクロサービスのバグによりテナントが他テナントのデータにアクセスできてしまうかを検証。
認可戦略の種類:
| 戦略 | 説明 |
|---|---|
| RBAC | ロールベース。各テナントに個別ロールを割り当て |
| 動的IAMポリシー | ユーザーIDに基づいてポリシーを動的生成 |
| ABAC | 属性ベース。タグに基づいてスコープ付き認証情報を生成 |
今回のアーキテクチャではABACを採用。Lambda Authorizerがテナント属性に基づいてスコープ付きの認証情報を動的生成します。
FIS実験:
SSM Documentを使って、Lambda関数内のKnowledge Base IDを意図的に別テナントのIDに書き換え。
ABACが正しく機能していれば、テナント1がテナント2のKnowledge Baseにアクセスしようとしても、IAMポリシーによってブロックされるはずです。
以下のようにJupyterNotebookをスピーカーが実行しながら説明する形式でした。
正直なところ、これを配布してくれた方が理解しやすかったと思います。
パターン3: サーバーレスアプリケーションテスト
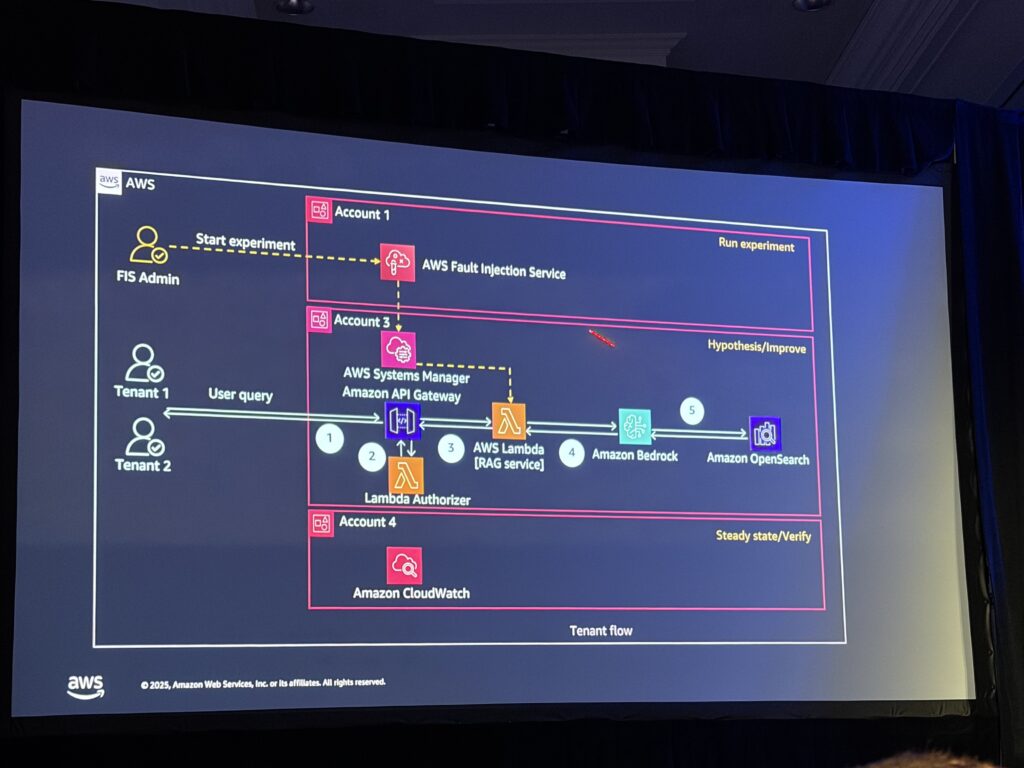
シナリオ: サーバーレスアーキテクチャにおける障害注入
Lambdaベースのアーキテクチャでも、FISを使って以下のような障害を注入可能:
- Lambda関数のレイテンシー増加
- HTTPエラーレスポンスの強制
- 依存サービスへの接続障害
「サーバーレスは高可用性・信頼性が高いが、それでも意図的に障害を注入してシステムの振る舞いを検証することが重要」
FIS実験テンプレートの構成
実験テンプレートはJSON形式で定義され、以下の要素で構成されます:
{
"actions": {
"tenant-isolation-bug": {
"actionId": "aws:ssm:send-command",
"parameters": {
"documentArn": "arn:aws:ssm:...:document/TenantIsolationBug"
},
"targets": {
"instances": "target-instances"
}
}
},
"targets": {
"target-instances": {
"resourceType": "aws:ec2:instance",
"selectionMode": "ALL"
}
},
"stopConditions": [
{
"source": "aws:cloudwatch:alarm",
"value": "arn:aws:cloudwatch:..."
}
]
}
ポイント:
- Actions: 実行する障害(複数可、順次または並列実行)
- Targets: 障害を注入する対象リソース
- Stop Conditions: 閾値を超えたら実験を自動停止
トラストでの活用可能性
このセッションを通じて、以下の点でトラストでの活用を検討したいと思いました:
1. SaaSアーキテクチャのレジリエンス検証
マルチテナント環境を構築する際に、FISを使った障害注入テストを開発サイクルに組み込むことで、本番障害を事前に防止できます。特にノイジーネイバー対策やテナント分離の検証は重要ですね。
2. ABAC(属性ベースアクセス制御)の採用
テナント分離の実装方法として、ABACは動的で柔軟性が高いアプローチ。Lambda Authorizerと組み合わせることで、セキュアなマルチテナント環境を構築できそうです。
3. AWS Resilience Lifecycle Frameworkの活用
障害テストを「やみくもに」行うのではなく、ビジネス目標(SLA/SLO)から逆算して計画的に実施するフレームワークは参考になります。
4. SaaS Builder Toolkitの検証
オープンソースで提供されているSaaS Builder Toolkitは、コントロールプレーン(テナント管理、課金等)のテンプレートとして活用できそうです。
参加セッション 3: AIM3329 | Build trust in production agents with AgentCore Observability ft Sony
3つめのセッションは、Agent Core Observabilityについてです。Day1・Day2で学んだAgent Coreの「オブザーバビリティ」に特化した内容で、さらにSony Groupの実際の活用事例も紹介されました。
登壇者はAgent CoreチームのProduct ManagerのVivekさん、Senior Solutions ArchitectのRajesh Kumar Raviさん、そしてSony Groupの大場さんです。
オブザーバビリティがないエージェントは怖い
セッションの冒頭で、Vivekさんがこんな例え話をしていました。
「飛行機に乗っていて、パイロットが『オートパイロットにします。コックピットをシンプルにするために計器類は全部外しました。テストでは墜落しなかったので大丈夫です』と言ったらどうですか?怖いですよね。オブザーバビリティのないエージェントも同じです」
この例えを聞いて、レビュー&テストをするのは当然として、本番デプロイ後もオブザーバビリティはこれまでのプログラム同様、Agentにも必要だと感じさせられました。
エージェント特有の課題

エージェントの監視が難しい理由として、以下が挙げられていました:
- 非決定論的: 同じ入力でも、コンテキストによって異なる行動をする
- ツールの連鎖: 1つのツールが失敗したとき、原因がどこにあるか特定しにくい
- ユーザー体験との紐付け: 「エージェントが応答した」だけでなく、「どれくらい時間がかかったか」「トークンをどれだけ使ったか」「ボトルネックは何か」を把握する必要がある
「見えないものは評価できない。オブザーバビリティは『あると便利』ではなく、信頼できるエージェントを運用するための基盤」これもなるほど。なるほどの連続でした笑
Agent Core Observabilityの機能
ここからようやく機能の紹介でした。
Agent Core Observabilityは一般提供(GA)されており、以下の機能を提供します:
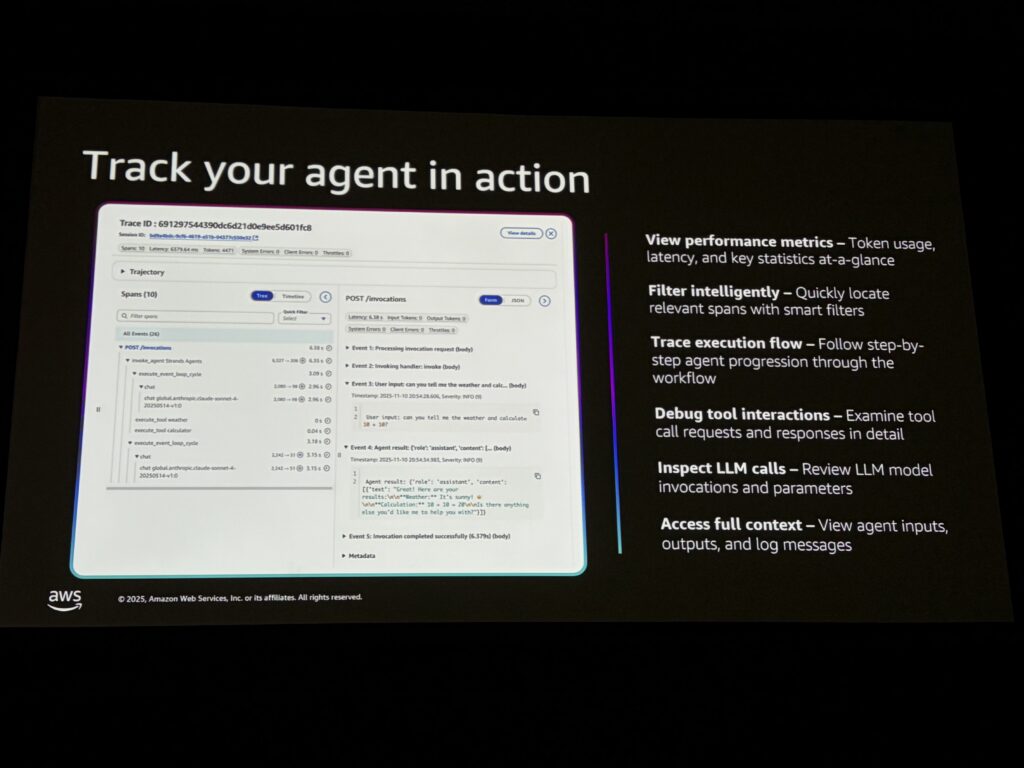

| 機能 | 内容 |
|---|---|
| パフォーマンスメトリクス | トークン使用量、レイテンシー、エラー率をリアルタイムで追跡 |
| ワークフロートレース | ユーザー入力→システムプロンプト→ツール呼び出し→最終出力までの全体パスを追跡 |
| ツールコール詳細 | エージェントがツールに渡したパラメータ、ツールの返却値を確認 |
| フルコンテキスト | エージェントが見たもの、生成したものすべてを確認 |
従来のインフラ監視(CPU、メモリ、ネットワーク)だけでなく、エージェントの推論やツール呼び出しの挙動まで可視化できるのがポイントです。
Open Telemetry対応
Agent Core ObservabilityはOpen Telemetry標準に対応しており、任意のエージェントフレームワーク(Strands、LangGraph、Crew AI、カスタム実装)で動作します。
「プロプライエタリ(Amazon製)なものを使う必要はない。オープンソースのエコシステムを活用してほしい」とはっきり言っていました。
対応しているインストルメンテーションライブラリ:
- open inference
- open elementary
- trace loop
- open lit
デモ: Strandsエージェントのトレース確認

Rajeshさんによるデモでは、Strandsベースのエージェント(メモリツール + Web検索ツール)を使って、CloudWatchでのトレース確認が紹介されました。
「ベガスを訪問するんだけど、レストランのおすすめを教えて」と質問すると:
- エージェントがまずメモリツールを呼び出してユーザーの好み(イタリアン好き、ベジタリアン等)を取得
- その情報を基にWeb検索でレストランを検索
- 最終的に3つのレストランをレコメンド
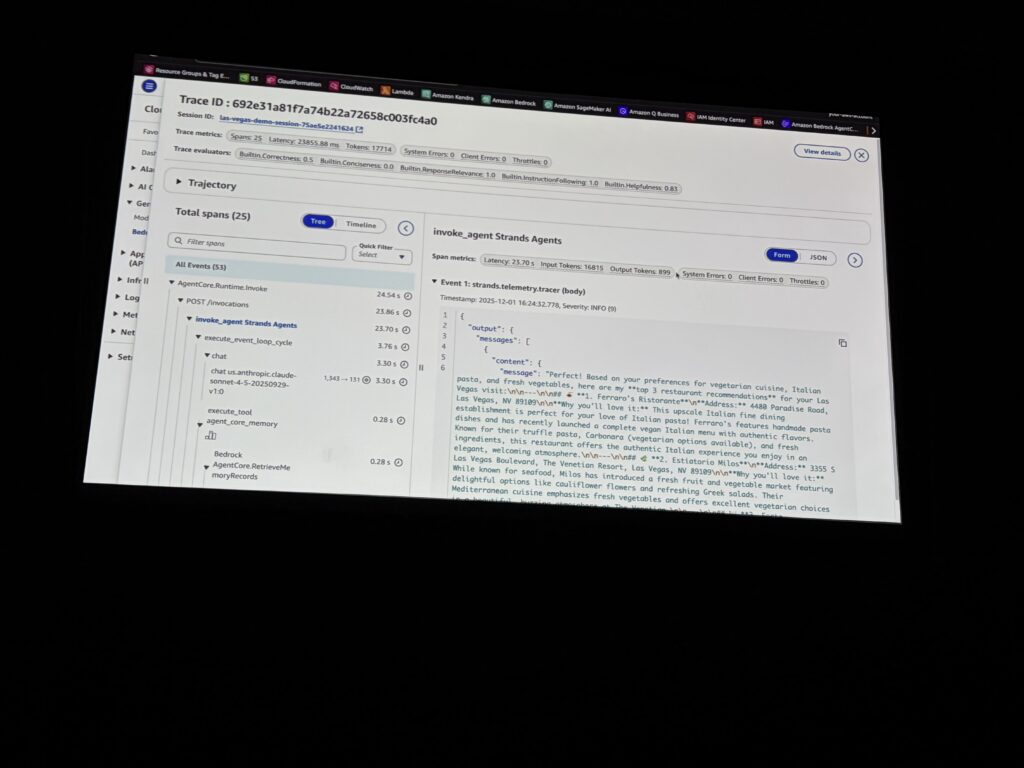
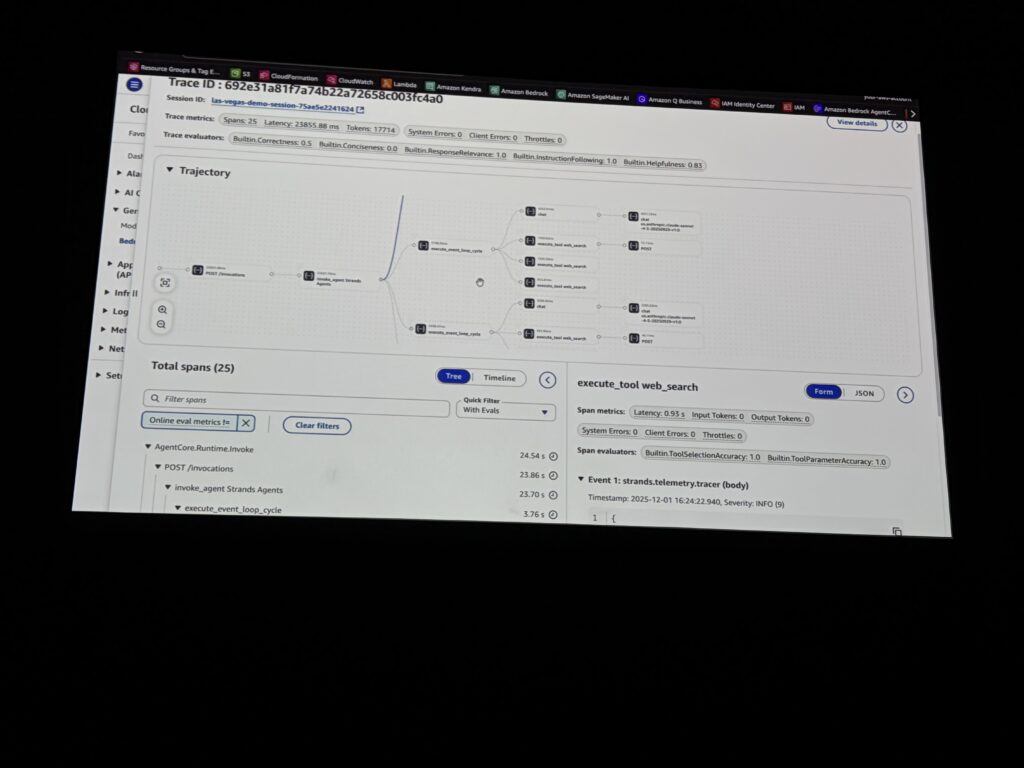
この一連の流れが、CloudWatchのダッシュボードでスパン(処理単位)として可視化されていました。どのステップで何秒かかったか、エラーはなかったか、一目で分かります。
ベストプラクティス
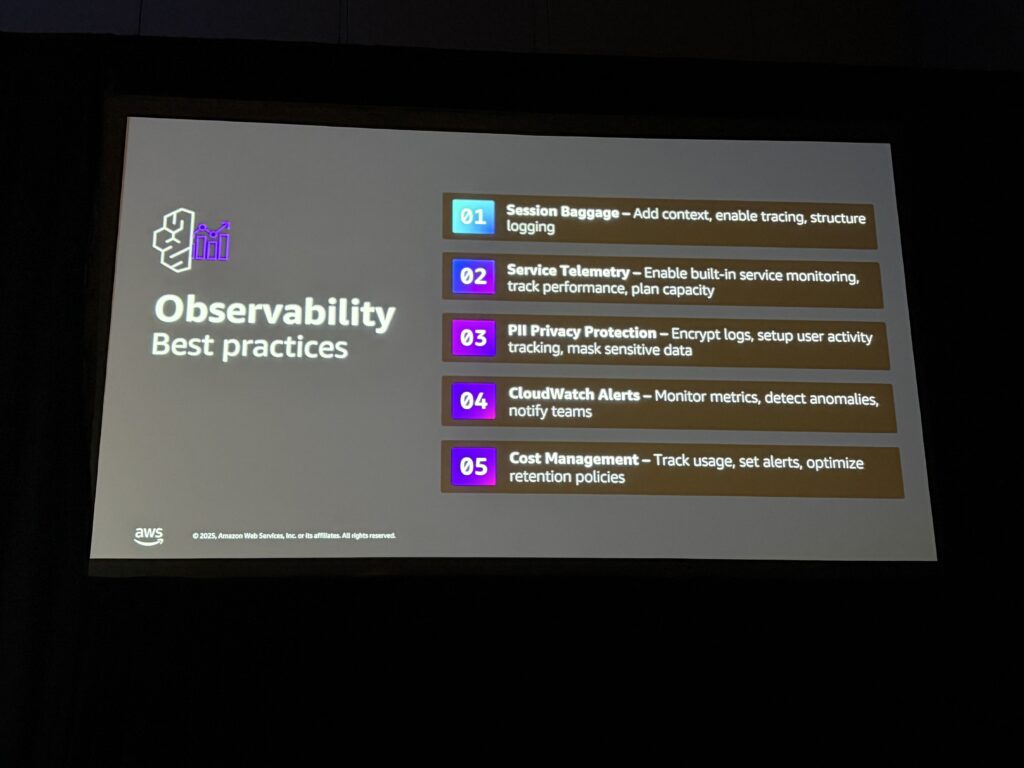
Rajeshさんから紹介されたベストプラクティス:
- セッションIDを付与する: ユーザーとの対話を一連の流れとして追跡できる
- サービステレメトリを有効化: メモリやゲートウェイのメトリクスも収集
- PIIデータの保護: CloudWatchのプライバシー保護機能でマスキング
- アラート設定: トークン使用量やエラー率にしきい値を設定
- コスト管理: ログの保持期間を設定してコストを最適化
Sony Groupの事例
後半は、Sony Groupの大場さんから実際の活用事例が紹介されました。大場さんはCDO(小寺CDO)直下のAI Acceleration Divisionで、グループ全体のAI推進を担当されているとのこと。
Day2のKeynoteで小寺CDOが登壇されていましたが、その裏側の技術的な話を聞けて非常に参考になりました。
Sony GroupのAI基盤
Sony Groupでは、AWS上に構築した生成AIプラットフォームで以下の規模を運用しているそうです:
| 項目 | 数値 |
|---|---|
| 対象グループ会社 | 280社 |
| アクティブユーザー | 58,000人 |
| 1日あたりの推論リクエスト | 15万件以上 |
| 今後数年の見込み | 300倍に増加 |
「ダウンタイムは一度もありません」
これはすごいですね。エンタープライズ規模での運用実績があるというのは心強いです。
なぜAgent Coreを選んだのか
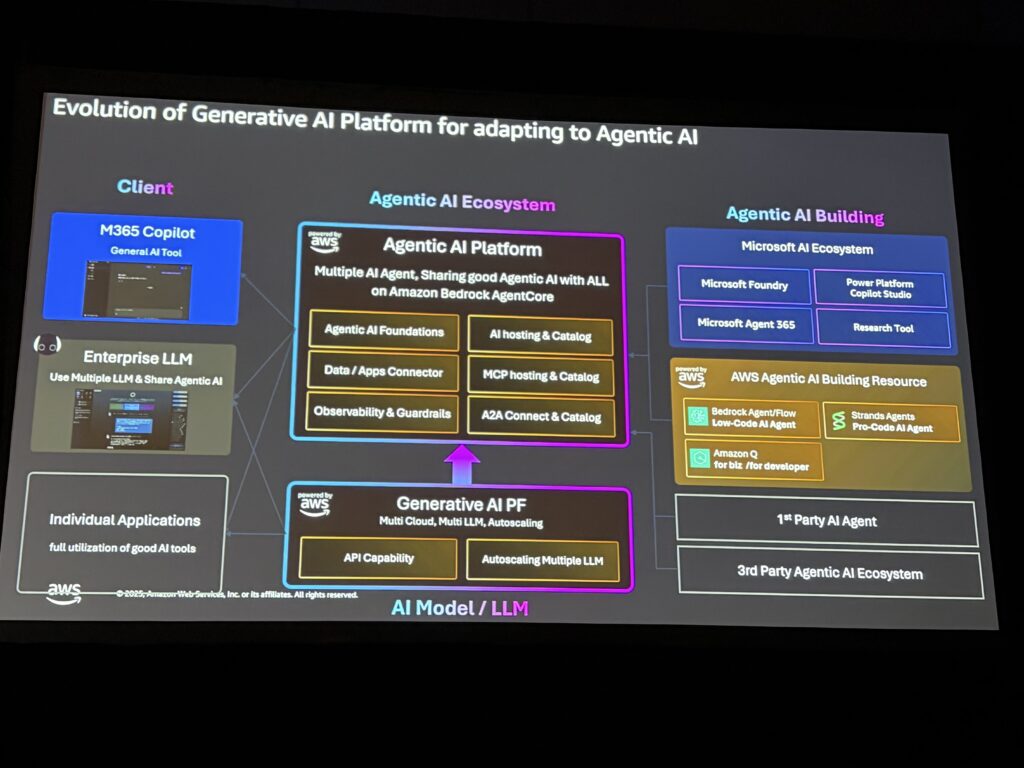
大場さんが挙げたAgent Core採用の理由:
- セキュリティ: エンタープライズレベルのセキュリティ
- オブザーバビリティ: 全てのAIエージェントの行動を一元監視
- スケーラビリティ: 15万→300倍への拡張に耐えられる
- クロスプラットフォーム接続性: Microsoft 365 Copilotなど外部AIエコシステムとの連携
特にクロスプラットフォーム接続性が重要だったそうです。Sony Groupでは既にM365 Copilotを多くの社員が使っており、それとAgent Core上のエージェントを連携させたいというニーズがあったとのこと。
AIツール審査・レビューの自動化
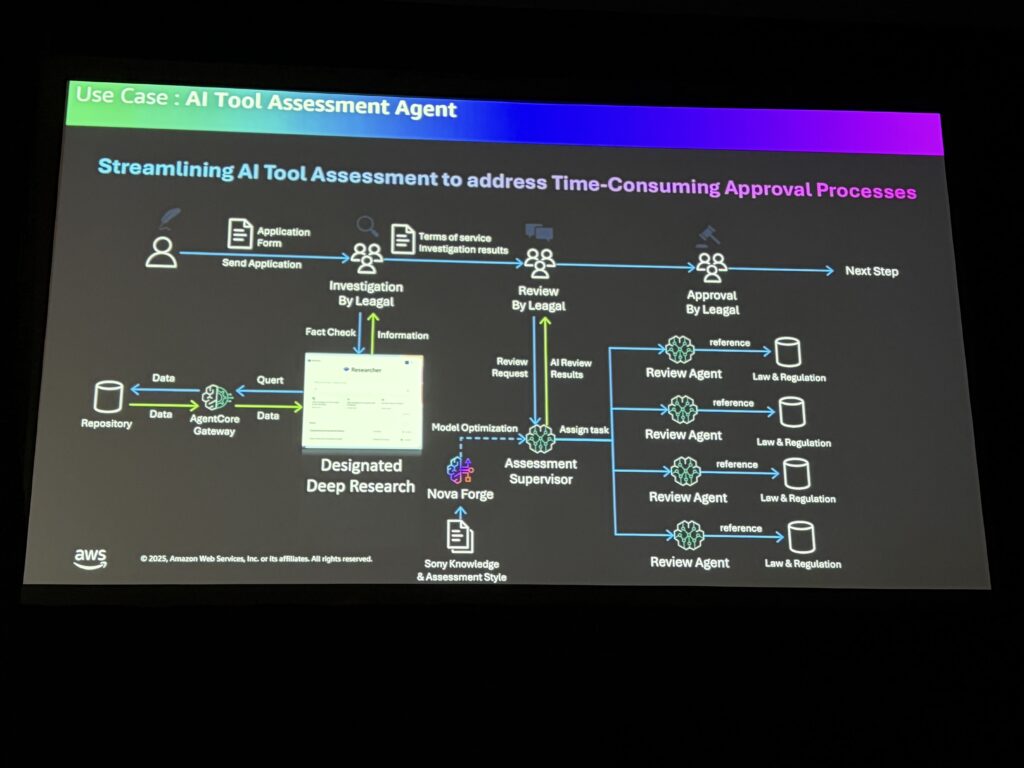
Keynoteで小寺CDOが言及していた「AIツール審査・レビュープロセスの効率化」の実際のソリューションが紹介されました。
- Novaモデルを使用
- 複数のAIエージェントが非同期で協調して、多角的な観点からレビューを実施
- Agent Core上にデプロイ
「複数のエージェントがオーケストレーションされて動くので、最終的な品質を上げるには全てのエージェントの行動を評価・理解する必要がある。だからエンドツーエンドのオブザーバビリティが必要」とのことでした。ここまで実装して既に運用されているのは、シンプルに感心してしまいました。
オブザーバビリティの民主化
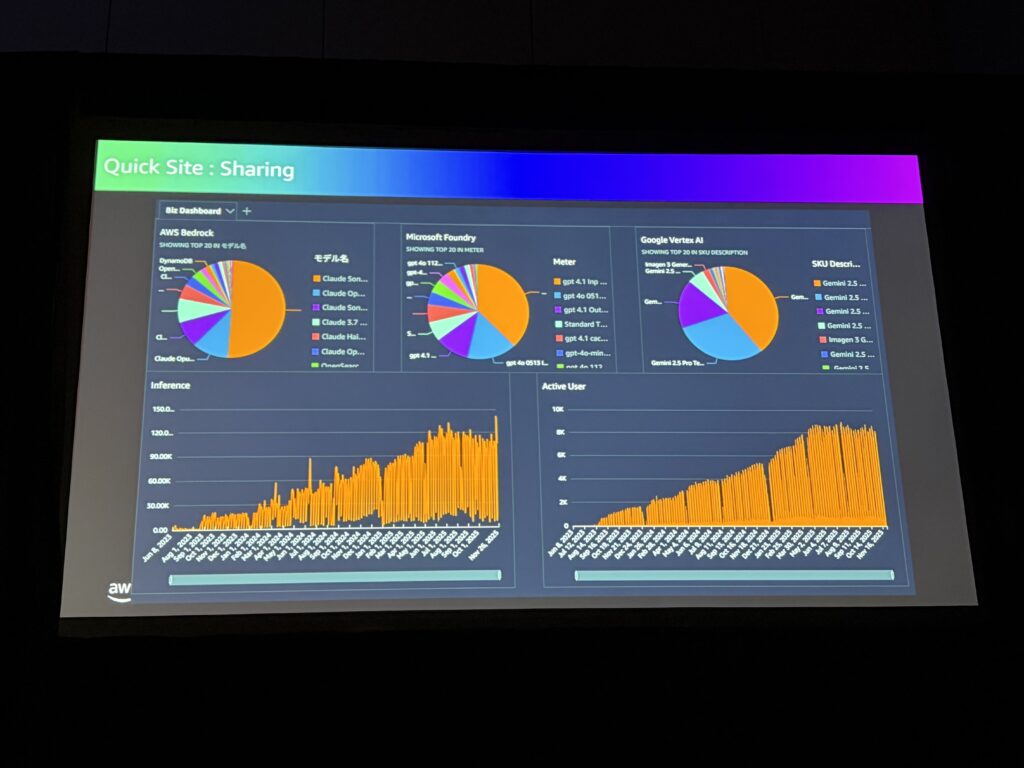
大場さんが強調していたのは、オブザーバビリティをプラットフォーム運用者だけでなく、エンドユーザーにも提供するという考え方です。
Amazon QuickSightを使って、ビジネスユーザーでも自分のAIエージェントの状況を確認できるようにしているとのこと。
「AIが全てのビジネスに組み込まれる世界では、エンドユーザーが自分のAIエージェントを可視化できることが重要。オブザーバビリティと品質改善サイクルを民主化することで、Sony Group全体のAI導入が加速する」
トラストでの活用可能性
このセッションを通じて、以下の点でトラストでの活用を検討したいと思いました:
1. Agent Core Observabilityの導入
Day1・Day2で学んだAgent Coreの運用面の話が具体的に聞けました。本番環境でエージェントを動かすなら、オブザーバビリティは必須ですね。
2. Open Telemetry標準の活用
プロプライエタリなツールに縛られず、オープンスタンダードでテレメトリを収集できるのは安心感があります。
3. セッションID管理
ユーザーとの対話を追跡するためのセッションID付与は、早い段階から設計に組み込んでおきたいポイントです。
4. QuickSightでの可視化
Sony Groupのように、ビジネスユーザー向けにもダッシュボードを提供するというアイデアは面白いですね。社内のAI利用状況を可視化する際の参考になりそうです。ここにQuick Suiteなど絡められると、さらに面白いと思います。
全体を通じての気づき
4日間を通じて「エージェント × マルチテナント × スケーラビリティ × 信頼性」というテーマで日々積み上げながら以下を学びました。
- Day1: Agent Coreによるマルチテナントエージェントの基礎
- Day2: ハンズオンでABACやメタデータフィルターを体験
- Day3: S3 VectorsやSaaS Anywhereでさらにスケールする方法
- Day4: Strandsによる実装、FISによるレジリエンステスト、オブザーバビリティ
「Agent Core + Strands」 という組み合わせがAWSの推奨スタックとして浮かび上がってきました。また、SaaSアーキテクチャではFISによるレジリエンステストとABACによるテナント分離が重要なパターンとして紹介されていました。
エンタープライズ規模での運用実績(Sony Groupの事例)もあるので、帰国後に今回学んだ内容の検証を進めていきたいと思います。
以上、本日分をもってAWS re:Invent 2025 現地レポートは終了です!!
朝から17時ごろまでセッションがあり、ホテル到着後も色々と別作業がありましたが、何とか「毎日現地レポート投稿」をやり遂げました!
来週以降は今回学んで試したいことが増えたので、それらのアウトプットとしてテックブログを更新していきます!お楽しみに!


